本文以 Apache Flink 为例,聊聊为什么 RocksDB 不是流计算引擎中理想的状态存储。Flink 中使用 RocksDB 作为大状态的存储后端,但在实际线上大规模的生产应用中,我们发现 RocksDB 和流计算场景的组合,即使在参数调优及技术优化后,也始终达不到预期的理想状态。
背景
RocksDB 是一个非常优秀的 Key-Value 存储,并且在经过 Facebook 多年的迭代和优化后,稳定性和功能的丰富性都能满足于各种主流场景的需要。我相信当开发者在进行 Embeded KV 存储选型时,RocksDB 仍然是一个很主流的选择,这可能也是为什么 Apache Flink 最初设计大状态 KeyedStateBackend 时,选择了 RocksDB 作为底层存储的原因吧(当然近年来也有不少优秀的存储如 Titan、TerarkDB 被设计出来解决新硬件和新场景下 RocksDB 不太给力的问题,在此不作讨论)。RocksDB 作为流计算引擎的状态存储,从使用者的角度来说,一般情况下并不会有很大的缺陷,但从分布式计算引擎角度来看,在实际线上大规模的生产应用中,我们会发现 RocksDB 和流计算放在一起,始终无法成为一个完美的组合。
RocksDB
RocksDB 使用 LSM-Tree 的结构,数据以类似 Log 的方式追加写入,不断产生新文件,并通过 Compaction 合并来去除不同文件中重复、过期、已删除的 Key-Value 数据。底层文件使用 SSTable 格式,SST 文件中的 Key-Value 数据按 Key 进行排序,并以一定规则划分为多个 Data Block,并基于 Data Block 的元信息来构建 Index Block,以保证较好的读取性能。
SST 文件在 RocksDB 中,以不同 Level(层级)的形式来组织。数据从内存中持久化成 SST 文件后,会先存在于 L0 层,当 L0 层数据到达 Compaction 触发条件时,数据会被 compact 到 L1 层,以此类推,存活时间越长的数据,最终到达的 Level 层级会越高。
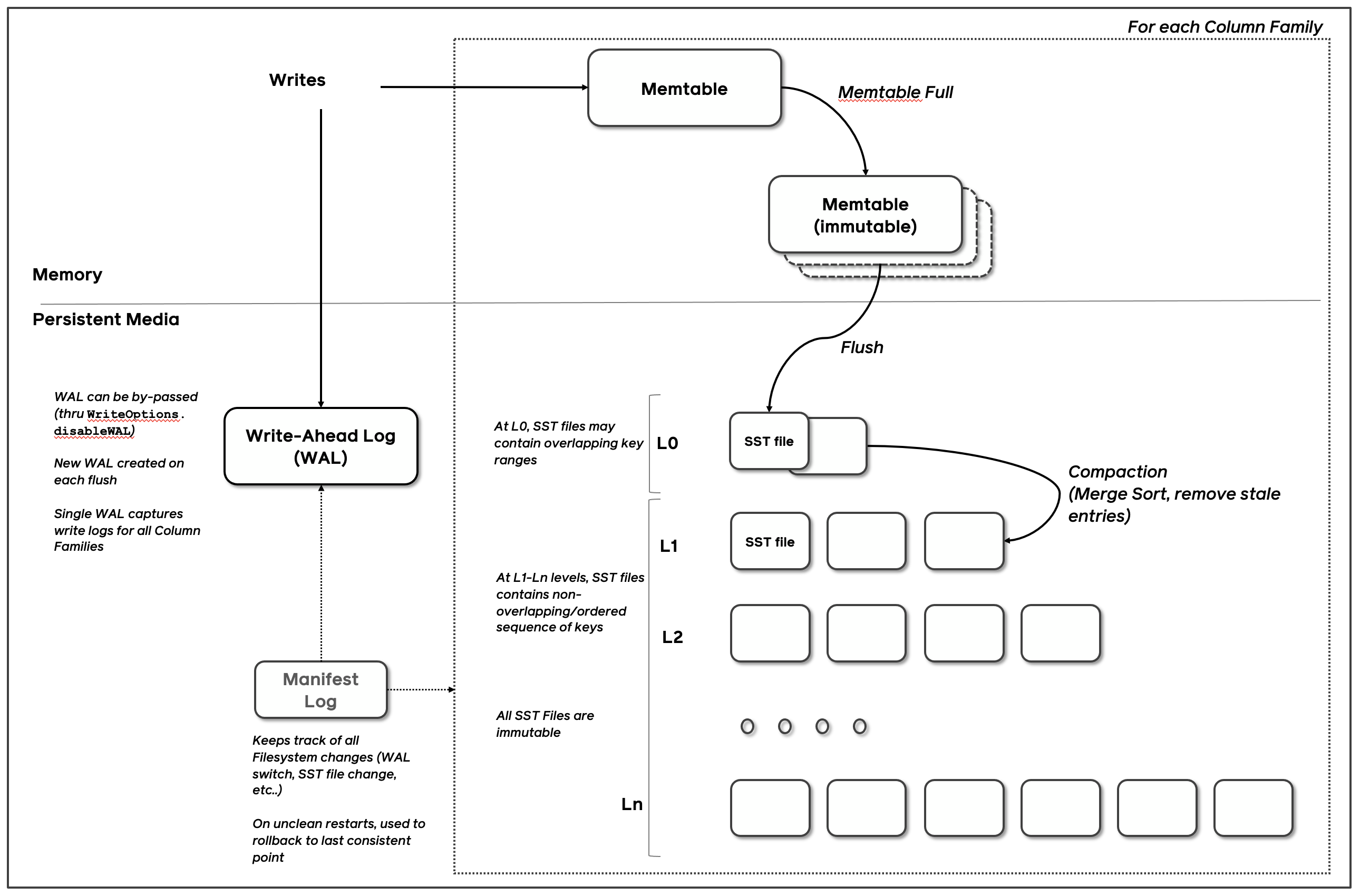
数据写入
如上图所示,数据写入会经过如下的过程:序列化、API 调用、写入 Memtable、持久化到 SST 文件。RocksDB 默认(可配置)在内存中维护了 2 个 Memtable,当用户调用 RocksDB 的写入 API 时,数据会同步写入到 Memtable 中,如果 Memtable 已经写满或达到其他 flush 条件,则会转换为 Immutable Memtable,并调度 RocksDB 的 flush 线程异步对其按 Key 整理、去重等操作,并持久化成 L0 层的一个新的 SST 文件。(如果用户开启 WAL,数据会同步写入到 WAL 中)
这里要注意,数据的写入一定是 append-only 的,这里的写入同样包括了更新。因为 RocksDB 采用 LSM-Tree 的数据结构,所以多次写入相同 Key 的数据,会在触发 Compaction 或者 Flush 操作时进行合并,而不是直接在 Memtable 中原地更新(update in-place)。这同样适用于 Delete 操作,对于单个 Key 的删除操作,在 SST 文件中以 (Key -> DeleteType) 的形式存在。(Memtable 使用的数据结构默认以 Skip-List 形式存在)
数据读取
这里先介绍 RocksDB SST 文件在不同 Level 的特性:
- L0 层:SST 文件资身是按 Key 排序,但 L0 层的 SST 文件之间是无序的,每个 L0 层的 SST 文件之间会发生 Key Range 的重合,也就是说相同 Key 的数据可能存在于在 L0 层的每一个 SST 文件中。
- L1 ~ Ln 层:多个 L0 层的 SST 文件达到 Compaction 条件后,与若干个 L1 层文件进行 Compaction 后形成新的 L1 层 SST 文件,L1 层 SST 文件之间不会出现 Key Range 的重合,也就是说相同 Key 的数据最多只会存在于 L1 层的一个 SST 文件中(L2 ~ Ln 层同理)。
读取数据时,数据可能存在于 Memtable、Block Cache、SST 文件中。读取操作分为两种类型:
- Point Lookup(点查):先从 Memtable 和 Block Cache 中尝试获取结果,如果没有找到则会按照层级查找 SST 文件。对于 L0 层 SST 文件,先通过 KeyRange 过滤出可能包含此 Key 的 SST 文件再进行查找;再对于 L1~Ln 层的文件进行二分查找定位对应的 SST 文件并进行读取。
- Range Scan:多路归并的思想,返回给用户的 Iterator 由多个 Iterator 组成:每个 Memtable、Immutable Memtable、L0 层 SST 文件、以及多个 L1 ~ Ln 层 SST 文件中构建 Iterator,并以多路归并的方式返回给用户具体的值。
上述的操作有很多默认的优化策略在此不一一列举了,比如点查操作中每个 SST 文件可以构建 bloom filter 来快速判断 Key 是否存在,遍历操作中每个 Iterator 会对底层的数据进行预读取以获得更少的 IO 次数。对于单个 SST 文件而言,它的文件结构如下所示,单个 SST 文件查询会通过对 index block 进行二分查找来定位到具体的 data block :
<beginning_of_file>
[data block 1] // 具体的 KV 数据
[data block 2] // 具体的 KV 数据
...
[data block N] // 具体的 KV 数据
[meta block 1: filter block] // Filter 信息,比如 bloom filter
[meta block 2: index block] // data block 对应的 index,查询中通过对 index block 进行二分查找来定位到具体的 data block
... (compression/range deletion/stats block)
[meta block K: future extended block]
[metaindex block]
[Footer]
<end_of_file>
Compaction 策略
为什么要进行 Compaction?:或者说 Compaction 有什么作用,我们都知道 Compaction 是将多个文件合并成一个文件的过程,在合并过程中会进行相同 Key 的去重,过期 Key 的删除等操作。一次 Compaction 可以简单看作将 N 个文件数据读取后,经过整理再重新写一遍的过程。在这里举两个极端的例子:
- 完全不发生 Compaction:SST 文件只存在于 L0 层,由于 L0 层不保证 SST 之间的 Key Range 不发生重合,所以数据读取需要访问很多 L0 层 SST 文件,在读取性能上会非常差。
- 持续发生 Compaction:假如每生成一个 SST 文件,我们就将它和其他 SST 文件进行 Compaction,那么数据写入的开销则会非常大。
可以看出,Compaction 策略的不同决定了读写放大,也决定了读写的性能,所以一个合理的 Compaction 策略其实是对读写性能的平衡,针对不同场景的需求,我们应该认真考虑其场景所适合的 Compaction 策略。RocksDB 默认提供三种 Compaction 策略,每个策略的触发条件都比较复杂,原理可看对应链接,这里仅描述一下它们的特点:
- Leveled Compaction(默认策略):Compaction 触发频率相对高,读放大低,写放大高
- Universal Compaction:Compaction 触发频率相对低,读放大高,写放大低
- FIFO Compaction:几乎不发生 Compaction,读放大高,写放大几乎没有
流式场景和状态访问
这里以 Apache Flink 为例来看看 Streaming State 在流式场景中是如何使用的。
场景一:WordCount,统计每 60s 内,每个 word 出现的次数:
对于每条数据:
- Window 算子根据 word 和时间戳,找到该数据所属的窗口
- 将 word、窗口标识符(即窗口起始时间和结束时间)和其他信息(如 KeyGroup)拼接成 RocksDB 的 Key 并序列化成 byte[]
- 调用 RocksDB API 读取窗口的中间结果数据并反序列化
- 使用新 word 更新中间结果
- 序列化中间结果并调用 RocksDB API 写入
场景二:A 流 Join B 流,逻辑如下:
SELECT *
FROM a, b
WHERE a.id = b.id
AND a.time BETWEEN b.time - INTERVAL '4' HOUR AND b.time
对于 A 流的每条数据(B 流同理):
- Join 算子收到 A 流数据后,遍历 B 流的状态数据列表并逐一反序列化
- 从 B 流的状态中找到符合 Join 条件的数据并拼接起来发送给下游
- 取出 A 流状态数据列表,反序列化后将新数据 append 到列表末尾
- A 流状态数据列表重新序列化并写入
我们发现,不管是窗口聚合还是双流 Join 的场景,我们可以看到状态存储的读写总是和当前数据所涉及的时间边界范围内的状态有关,比如窗口聚合场景中只会对数据所在的窗口进行读写,双流 Join 场景中只会对 Join 条件中的时间范围内状态进行读取和写入,而并非像 Web 服务中的 ACID 一样去操作所有时间段的数据。这个特性点恰好也和我们常说的,越接近当前时间的数据价值越高,越久远的数据价值越低是不谋而合的。
RocksDB 作为状态存储
Apache Flink 目前使用 RocksDB 作为状态存储,在小状态场景下,可以使用少量冗余的资源来掩盖状态存储带来的问题;在大状态场景或是数据倾斜的场景下,我们为了流式作业的高性能吞吐需要,往往需要付出非常大的 overhead。
选择哪一种 Compaction 策略?
上面提到 RocksDB 内置的三种 Compaction 策略,以 Leveled Compaction 为例,会出现以下问题:
写放大问题:Leveled Compaction 针对的是少写多读的场景,而在流式计算中,新数据的处理通常都会产生多次的状态访问和状态更新,大部分场景更接近于读写比例 1:1(比如典型的滚动窗口计算场景中间结果的 update)。频繁的数据写入会造成 Leveled Compaction 上各个层级频繁触发 Full Compaction,尤其是每次 Checkpoint 都会强制产生一个 L0 层文件,很容易就达到 Leveled Compaction 的默认触发条件。
共振问题:如果用户侧有 TaskManager 整体的 CPU 监控,我们很容易看到,每 4 个 Checkpoint 触发时间点,就会有一次 CPU 陡增的现象,并且作业的吞吐会出现明显的下降,这是因为 RocksDB 的 Leveled Compaction 默认在 L0 层的 SST 文件数量达到 4 个时就会触发 L0->L1 层的 Compaction 操作,而各个 Task 的 Checkpoint 操作通常在一两分钟内同时触发,所以此时会导致 Compaction 共振问题,CPU 陡增也会影响 Task 正常的数据处理线程。
潮汐问题:通常来说,数据流量越大,RocksDB 的写入越多,Compaction 的触发越频繁。而恰好流式场景会有非常典型的潮汐现象,高峰和低峰流量往往会差好几倍,但是实际情况中,我们会发现 Compaction 的资源开销越在高峰阶段,开销越大,而真正处理作业逻辑的算力更加不够,只能通过继续增大资源的方式来缓解问题,也就造成了低峰时期的资源利用率会非常非常低。
对于 Universal Compaction,会稍微好一些但仍然有类似的问题。这里我们可以着重看一下功能最少,表面看起来最鸡肋的 RocksDB 的 FIFO Compaction,描述摘自 wiki:
FIFO compaction style is the simplest compaction strategy. It is suited for keeping event log
data with very low overhead (query log for example). It periodically deletes the old data, so it's
basically a TTL compaction style.
In FIFO compaction, all files are in level 0. When total size of the data exceeds configured size
(CompactionOptionsFIFO::max_table_files_size), we delete the oldest table file. This means that
write amplification of data is always 1 (in addition to WAL write amplification).
FIFO 的方式,其实是在 L0 层以 SST 文件的形式维护了一个“流”,存活时间越长的数据优先级越低,越有可能被 TTL 删除,这样就和流式场景比较相像了。不过使用 FIFO Compaction 策略会导致 L0 层文件过多,数据读取性能变差,RocksDB 也提供了一些非常简易的 Compaction 策略来缓解这一问题,我们也可以通过增加 bloom filter + cache 的形式来减少数据查询的文件 IO 次数。
在我看来 FIFO 是三者中最适合流式场景的 Compaction 策略,但是由于没有和 Flink 内部机制打通(比如 TTL 两边不对齐),可能会出现数据丢失的风险,我们也不推荐用户进行使用。(当然,我们可以通过 RocksDB 的 API 来自定义 Compaction 策略,或者去稍微改改 Flink or RocksDB 的源码以满足需求)
Embeded Storage 和分布式计算
RocksDB 是 Embeded Storage,Embeded 也就意味着在分布式计算应用中,每个 Task 维护的 DB 实例是相互隔离的,很难拿到一个全局视角以做出最优的方案。关于状态存储,我在 Hazelcast Jet 论文 中有提到过 Embeded 和 Distributed Storage 的对比,这里从另一个角度讲讲。
以上面提到的 Compaction 共振问题为例,如果我们像 HBase 一样,可以通过 jitter(抖动因子参数)将各个 Compaction 操作的时间错开,那么我们看到的作业输出可能是平稳且符合预期的。除此之外,扩缩容问题也是类似的,Apache Flink 中作业的扩缩容,对应着状态扩缩容示意图如下:
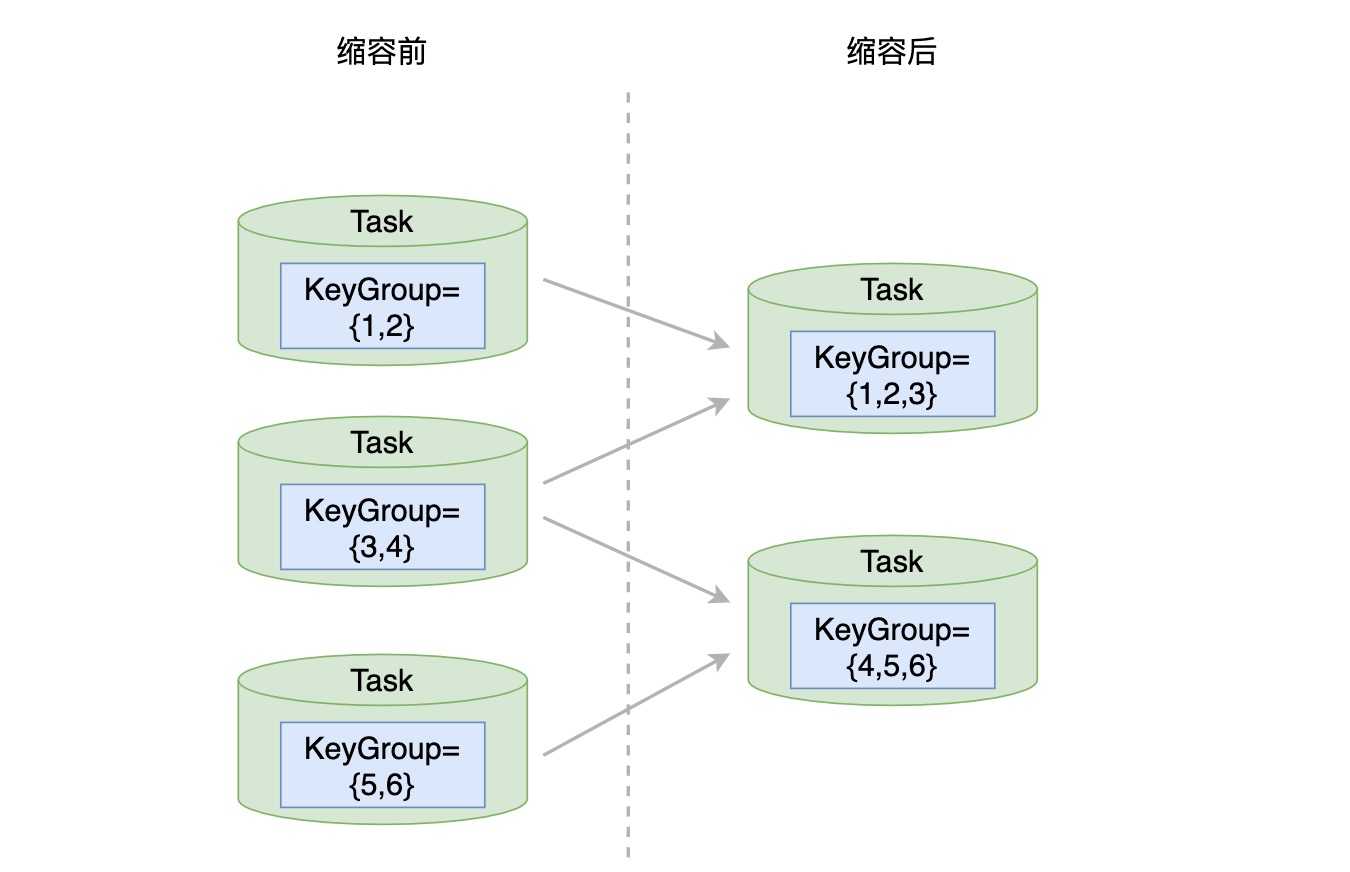
假设算子最大允许存在 6 个 KeyGroup(任何数据都会被映射到 6 个 KeyGroup 范围内),缩容前这个算子有 3 个 Task,分别负责 {1,2},{3,4},{5,6} 三个 KeyGroup 的数据处理,在算子并行度从 3 调整为 2 后,新的 2 个 Task 需要处理 6 个 KeyGroup 的数据,则对应负责的 KeyGroup Range 就变成了 {1,2,3} 和 {4,5,6}。这也是流式计算中应对扩缩容的通用做法,每个 Task 会负责一定 KeyGroup Range 内的数据处理,在进行扩缩容时,KeyGroup Range 会根据 Task 的数量进行重新分配,相对应的,每个 Task 负责的 KeyGroup Range 发生变化,也就意味着之前不同 Task 中 RocksDB 实例之间需要进行数据迁移和合并。从单机存储的设计角度来考虑,在设计之初便是为了服务于单机场景,往往不会为这种扩缩容情况作过多考虑(更别提流式计算这类对扩缩容耗时敏感的场景了)。
资源竞争
资源竞争的问题上面已经提到,RocksDB flush 线程和 compaction 线程所用的 CPU 资源,会和作业处理数据线程的 CPU 资源产生竞争。分布式计算任务,部署在 Yarn 或者 K8s 上,为了保证其他资源(如 Memory)不到达瓶颈,通常部署的一个实例(container)上 CPU 数不会特别多,也就是个位数的级别。在这种情况下,RocksDB 的异步操作对于作业处理产生的资源竞争影响就会非常大。当然,RocksDB 的 Compaction 线程会被设置为 low-priority,但这在流式场景中数据持续流入的情况下并不起太大的作用,而且当 Compaction 过于滞后时,RocksDB 会出现 Write Stall 等现象,让 Task 的处理线程在短时间内完全 hang 住。
其它
除了上述问题,篇幅原因,在这里简要概括过去在工作中遇到过的其他问题(或是在流式场景中可以改进的问题):
- 序列化:在 Flink 的使用下,RocksDB 并不能很好地处理 Read-Modify-Write 的场景,尤其是用户数据结构较为复杂时,现象会非常明显,一次 Update 即意味着一次读取时的反序列化和一次写入时的序列化,很多用户自定义 UDAF 时不注意存储数据结构的复杂度,这里很容易出现瓶颈。
- 压缩:数据的压缩和解压缩,同上。
- 小文件:频繁 update,造成生成的 SST 文件都是小文件。
- 时间语义:缺乏丰富的时间语义(比如事件时间)
- retract:retract 操作会造成大量 delete 从而降低 scan 和 seek 的性能
….
总结
本文主要介绍了 RocksDB 的相关原理和与流式场景结合时存在的若干问题。这并不影响用户继续使用 RocksDBStateBackend 作为大状态的存储后端,只是期待未来会有一个跟流式场景更加贴合的 Storage 吧,可能是 Embeded Storage,也可能是 Distributed Storage,随着流式场景越来越流行,这件事情一定会有人在做或者即将准备做的。