原文:Hazelcast Jet: Low-latency Stream Processing at the 99.99th
Percentile,Hazelcast Jet 是一个流处理引擎,整篇论文通读下来,它的定位和当前广为应用的流计算引擎 Apache Flink 和 Spark Streaming 又有些不同,详见以下文章的解析。
背景
流计算在过去几年越来越流行,业界中存在着很多针对不同领域的流计算系统,比如 IoT,物联网,大数据计算等场景,都使用了不同的底层架构。但是在这些架构中,它们普遍专注于上层应用的功能丰富程度,而并未将端到端的 latency、以及 Embeded 部署支持作为其发展目标。
In-Memory Data Grid(IMDG)是由 Hazelcast 开发,基于内存的分布式对象存储系统,在 Hazelcast 使用 IMDG 服务客户的过程中,发现越来越多客户将 IMDG 使用在偏计算的场景里,所以 Hazelcast 决定开发 Jet 以满足其客户在流计算场景低延迟的需求。
技术架构
整体项目架构如下图所示(摘自论文):
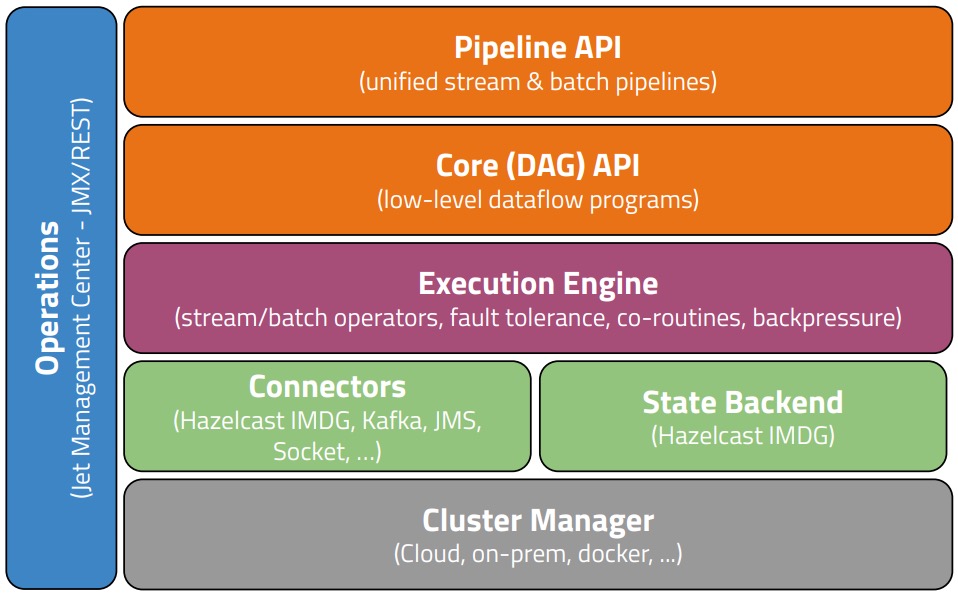
- Pipeline API:流批一体的 API(High-Level)
- Core API:用户可利用 Core API 进行 DAG 的定制和更深层的调优(Low-Level)
- Execution Engine:算子计算
- State Backend:使用 IMDG 作为流式计算中的状态存储
设计亮点
Graph 构建:
- 利用 Operator Chaining 来减少 Operator 之间的数据拷贝
- 尽可能地在 Operator 部署上做到 Locality 亲和性
- 非 Local 的 Operator 之间传输时,新增 Exchange Operator 进行协助网络传输(Exchange Operator 可以做一些聚合的 Combine 操作)
Tasklets 和线程:
Tasklets 是 Hazelcast Jet 中最小处理单元,多个 tasklets 共享一个 Cooperative 线程。Tasklets 主要用于作业的处理操作,比如 aggregate、join 等,对于 Blocking-IO 如网络请求、磁盘读写等,需要放到 Non-Cooperative Thread 进行。比如在 DAG 中,Source 和 Sink 往往是需要和外部组件进行交互的算子,所以 Source 和 Sink 是需要在 Non-Cooperative 线程中执行。这里的 Tasklets 和 Cooperative 线程类似于 Event Loop 的通信模型。
针对 JVM 的优化:
- 减少数据的拷贝和传输:比如上面提到的尽量将不同算子 chain 在一起;部署上尽量 Local 化;同节点算子使用 Shared Memory 进行通信等
减少 GC 抖动:使用 Java 应用不可避免遇到 GC 的问题,FGC 会造成处理停顿,导致作业 latency 出现抖动,在这里 Jet 依旧利用线程模型来减少 GC 带来的数据处理线程的抖动:
i. 利用 Cooperative Thread 和 Tasklets 模型来进行数据处理,不引入多余的处理线程,减少 CPU 的线程切换
ii. Cooperative Thread 数量会略少于节点上 Core 的数量,以预留出一部分 CPU 给 GC 线程
状态管理
上面提到 Jet 使用 Hazelcast 自研的分布式 Object Store IMDG 作为状态存储,实际上在部署时,Jet 也同样会考虑算子和 IMDG 状态数据的亲和性。比如 IMDG 中有三个节点,分别负责以下 Key Space:
- Node 1:负责 Key Space = (P1, P4, P7, P10)
- Node 2:负责 Key Space = (P2, P5, P8, P11)
- Node 3: 负责Key Space = (P3, P6, P9, P12)
DAG 中出现 Key-Hash 的网络传输时,Key-Hash 后下游的每个 Operator 会分配其固定的 Key Space,Jet 会根据其 Key Space 部署到对应的 Node 以保证最大程度的 State Local Access。当 IMDG 集群节点出现 failure 时,IMDG 中 failure 节点的状态数据对应的 Replica 会进行重新复制,并将新数据分配到各个节点上。
容错性
快照制作使用 Chandy-Lamport 算法进行一致性快照制作,Source 算子触发 snapshot 后下发 barrier,下游算子收集齐 barriers 后进行 save state 的操作,等待所有算子都完成 save state 操作后,所有已经 saved state 会被提交到 IMDG 上。作业恢复也是从 IMDG 上寻找最新快照进行恢复。(更多的细节没有提到…)
上下游 Connector 提供事务机制的情况下,通过 Two-Phase Commit 的机制,可以实现 Exactly-Once 的语义。
探讨: Embeded Storage vs Distributed Storage Service ?
状态管理上 Jet 使用了外部存储 IMDG 而不是 Embeded Storage 来做这件事情。使用 Embeded Storage 还是 Distributed Storage Service 来做状态管理,这件事情确实很值得说一说。
目前 Apache Flink 中使用 RocksDB(Embeded)来作为状态存储,优势和劣势都比较明显:
- 优势
- Storage 生命周期由作业托管,简单易用,运维成本低
- 状态访问都在本地,满足流式计算高吞吐的需求
- 借助 Storage 的 checkpoint 机制来完成流计算 checkpoint 同步阶段
- 劣势
- Embeded Storage 自身不具有容错能力,需要借助分布式文件系统(HDFS)来实现状态的容错
- 扩缩容恢复时需要重新构建 Storage,涉及到状态数据的重新分配,往往会比较复杂和耗时
- 如果使用磁盘,则对硬件会有要求
而在实际的生产环境实践中,我们发现 Embeded Storage 带来的劣势,会随着作业个数和状态大小的增加,而不断放大,比如作业个数越多,checkpoint 产生的 HDFS IO 越大,对应着 HDFS 上小文件也越多;状态越大,扩缩容恢复的时间越长。而使用 Distributed Storage Service,恰好又将 Embeded Storage 的优势和劣势颠倒过来:
- 优势
- 分布式特性自带容错
- 扩缩容恢复有很多选择,可以让算子通过 Remotely 访问 State,也可以做状态数据的迁移等
- 状态实际的存储形式可以有一个更全面的视角,实现更好的存储结构优化,提高资源利用率
- 劣势
- 额外维护一份分布式存储组件
- 性能会有一定损失,远程访问状态,至少需要序列化 + 网络传输两个过程,而在 Embeded Storage 中这两个操作都可以优化掉
- 需要自行实现 checkpoint 机制,由于流计算中通常是一致性的全局快照,而分布式存储没有办法获取流式计算任务的算子信息和分布情况,所以只有从计算任务的视角进行 checkpoint 定制,才能实现全局一致性
孰优孰劣,其实本质上是对两种方式在劣势上的偏好,如果流式计算的集群规模偏小,则 HDFS 不容易到达瓶颈,扩缩容恢复的成本也比较可控,那么继续沿用 Embeded Storage 也是很好的选择;如果流式计算的集群规模大,不在意多维护一个分布式组件,并且能够基于 Distributed Storage Service 去重新优化流计算里的快照逻辑,那么 Distributed Storage Service 也是一个选择。
中间的选择有没有?也有,比如基于 Embebed Storage 优化其扩缩容性能、和 HDFS 交互时进行小文件合并等优化操作;或者像本文一样,通过 Locality 亲和性调度来缓解远程状态访问在性能上的问题。(相关内容有很多,在此不一一赘述)
总结
整体读下来,很多内容和 Apache Flink 的实现还是比较同质化的,比如容错、语义等,比较大的区别是 IMDG,在状态管理上 Jet 使用了外部存储而不是 Embeded Storage 来做这件事情,算是提供了一个比较好的思路。除此之外,Hazelcast Jet 确实找了一个比较好的切入点:
- 低延迟
- 支持 Embeded 和分布式部署
关于低延迟,目前在企业实践中普遍使用 Flink 和 Spark Streaming 来进行流计算,两者都不能提供稳定的端到端延迟保证,所以更多是用在离线和准在线的数据计算,而不是提供 ToC 业务的指标(比如金额相关计算等);而 同时支持 Embeded 和分布式的部署,这在流计算引擎中也是少见的,比如 siddhi-io 是一个 Embeded 的流计算引擎,但是不支持分布式部署。在实际生产中,我们更多见到的是在线和 ToC 等对延迟和准确性极度敏感的服务,会使用 siddhi、drools 等 Embeded 引擎来做,而准在线,离线的报表服务会使用 Flink 和 Spark Streaming 来做。
回到本篇论文,其中提到的 Pipeline API,Tasklets and Cooperative Thread 模型,在生产实践都广为应用。低延迟的目标,更多是通过 DAG 中的细节做调整,比如同一 Node 内不同算子数据交互使用 Shared Memory,预备冗余资源供 GC 消耗,使用 Combine 算子进行预聚合等,整体的架构上,除了使用 IMDG 外,似乎并没有太多创新点。