Watermark是流式处理中的一个基础概念,关于Watermark的概念有很多,在这里不做阐述。
Watermark特性
这不是官方的表述,我根据自己的认知觉得Watermark有以下几个特点:
- 基于已有数据生成Watermark,Apache Flink生成Watermark有Punctuated和Periodic两种方式,但大多数人的使用方法都是基于已有数据生成Watermark。这个会给我们带来一定的问题,这个在后面讲到。
- 只允许递增。这个特性让我们需要对可能产生”脏”Watermark的情况进行判断,比如需不需要对出现的未来时间做处理等。
- StreamInputProcessor从多个channel中收到的多个Watermark取最小值传递给下游算子。这也可能成为在数据倾斜时,导致程序OOM挂掉的原因之一。
isWatermarkAligned
在Watermark相关源码中经常可以看到Watermark对齐的判断,如果各个子任务中的Watermark都对齐的话,那是最理想的情况。然而实际生产中,总会很多意外。这里有两个极端的例子。
一条数据流长时间没有数据,其他流数据正常。
出现这种情况的原因有很多,比如数据本身是波峰状,数据被上游算子过滤掉等。刚刚提到,下游算子的Watermark取决于多个上游算子Watermark的最小值,那么如果一条数据流长时间没有数据,岂不是会造成Watermark一直停留在原地不动的情况?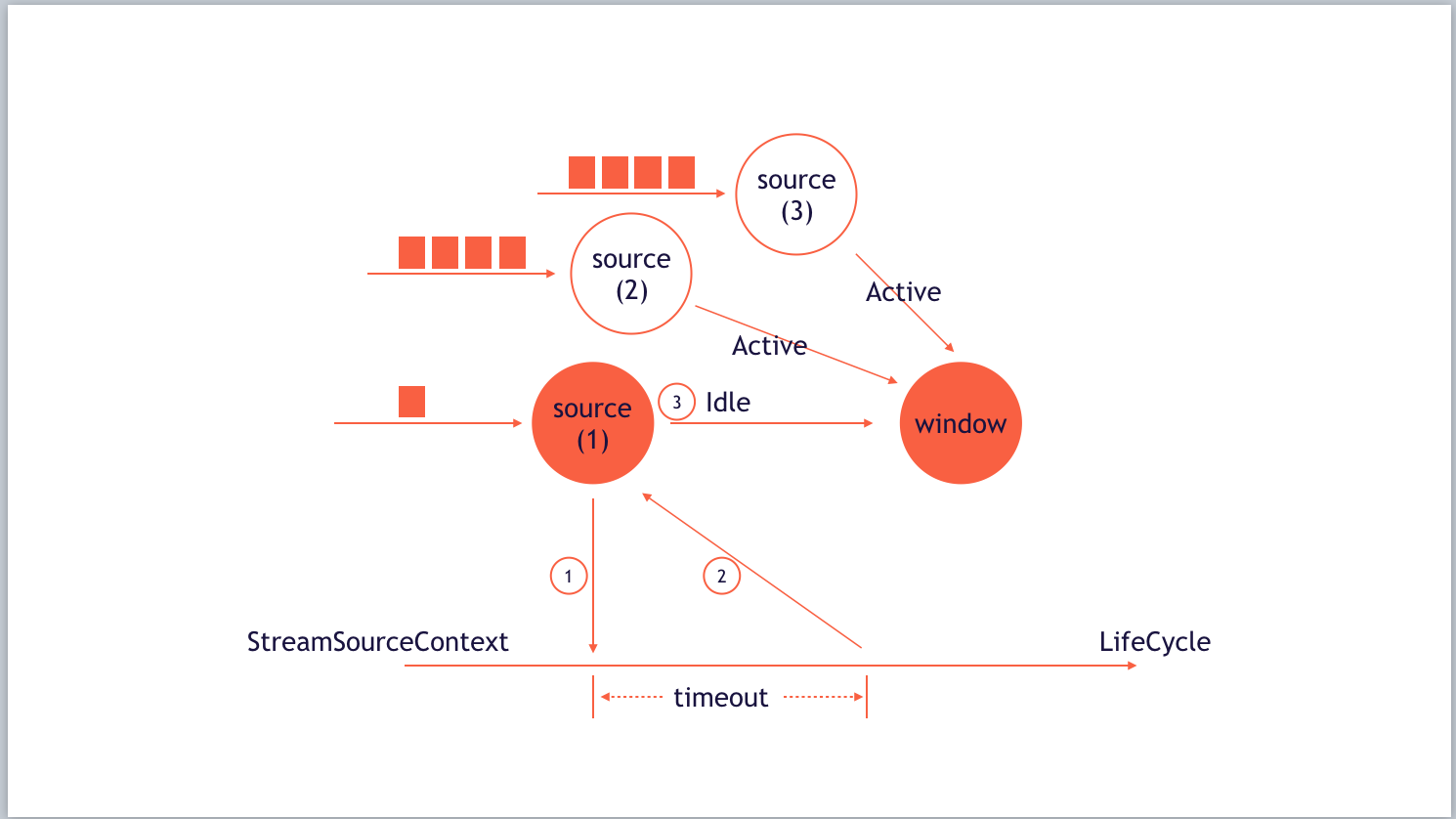
当然不会,针对这种情况,Flink在数据流中实现了一个Idle的概念。 用户首先需要设置timeout(IdleTimeout),这个timeout表示数据源在多久没有收到数据后,数据流要判断为Idle,下游Window算子在接收到Idle状态后,将不再使用这个Channel之前留下的Watermark,而用其他Active Channel发送的Watermark数据来计算。
如上图所示,Source(1)在接收到数据后,会触发生成一个timeout之后调用的callback,如果在timeout时间长度中,没有再接收新的数据,便会向下游发送Idle状态,将自己标识为Idle。
数据倾斜。
假设单条数据流倾斜,那么该数据流中处理的数据所带的时间戳,是远低于其他数据流中事件的时间戳。
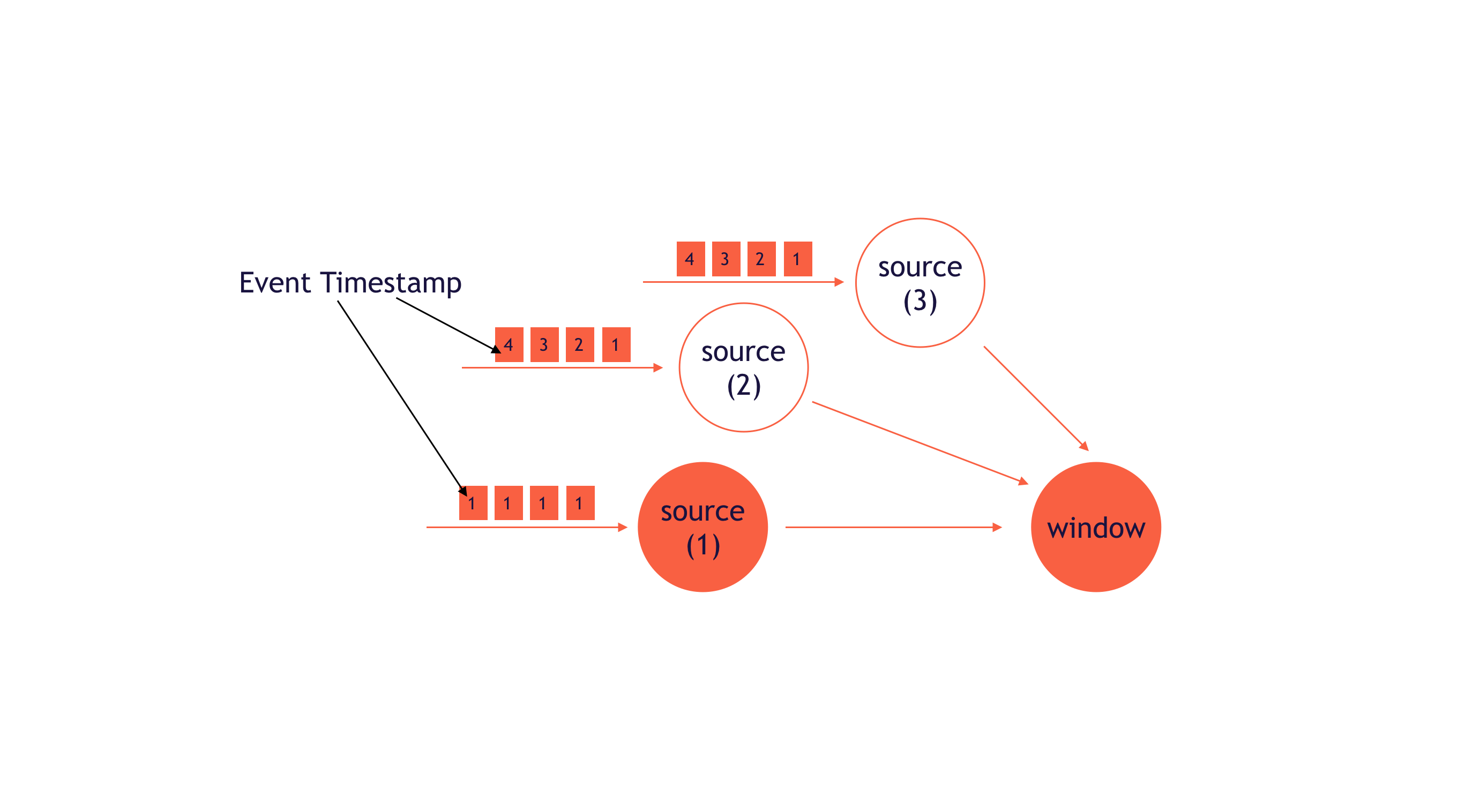
如图所示,假设Watermark设置为收到的时间戳-1,那么Window的Watermark始终都保持在0,这会导致Window存储大量的窗口,并且窗口状态无法释放,极有可能出现OOM。这个问题目前没有好的解决办法,需要具体情况具体分析了。
State Of WatermarkOperator
stream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[PatternWrapper] {
override def getCurrentWatermark: Watermark = new Watermark(System.currentTimeMillis() - 15000)
override def extractTimestamp(element: PatternWrapper, previousElementTimestamp: Long): Long = {
System.currentTimeMillis()
}
})
我们都知道,用户可以通过显式调用这种方法来实现Watermark,那么对于这种方法,本质上是生成了一个WatermarkOperator,并且在Operator中计算Watermark传递给下游的算子。
此时问题来了,刚刚提到Watermark是由已有数据产生的,那么在程序刚恢复还没有发送数据的时候怎么办?当然不能选择当前时间,这样的话,稍晚一点的事件就被过滤掉了。
这就引出一个问题,Watermark是不会存储在Checkpoint中的,也就是说WatermarkOperator是一个无状态算子,那么程序启动时,Flink自身的逻辑是初始化Watermark为Long.MIN_VALUE。由于我们架构设计的原因,对脏数据非常敏感,不允许发送过于久的历史数据,于是我们将WatermarkOperator的算子改成了有状态的算子,其中为了兼容并行度scale的情况,我们将Watermark设置为所有数据流中Watermark的最小值。具体的JIRA可以看FLINK-5601中提出的一些方案和代码改动。