闲扯
最近Spark2.3正式发布,流处理不再试Beta版,Spark的Structure Streaming几乎是拥有了Flink的所有功能,生态社区做得好就是不一样,Flink该加把劲了…
引言
Exactly-once是一个经常提到的语义,也是程序开发中,需要尽可能做到的一个理想状态。这种语义其实放在分布式程序中有很多种理解,比如读取数据源Exactly-once,Process过程Exactly-once,存储数据Exactly-once,但我们常用的理解方式是End-to-end的语义,也就是说,每一个输入,只会影响一次输出。
Exacly-once
既然是分布式的程序,要达到Exactly-once的语义,在输出那层,就应该只有两种情况,要么一起输出,要么一起不输出。Flink为此就提供了一个TwoPhaseCommitSinkFunction的抽象类用来完成这一语义,JIRA,PR。
顾名思义,此类利用了Checkpoint机制提供了两个Phase(步骤):
- preCommit()
- commit()
preCommit()示意图:
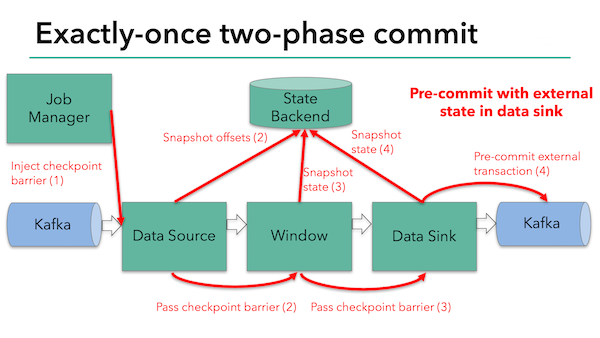
这个示意图描述了一个从kafka读取数据,采用WindowFunction做处理,最后再存储到kafka里的数据流。在Checkpoint过程中,首先在Datasource上用barrier把数据流切成两部分并不断传递下去触发snapshot,以保证所有的snapshot都是在相同一部分数据下产生的,最后一个阶段调用Sink函数的Pre-commit()表示,所有的Taskmanager的Sink都可以进行commit()操作了。
注意此时并不能直接commit,因为taskmanager之间彼此并不知道其他的节点是否准备好了commit!
commit()示意图:
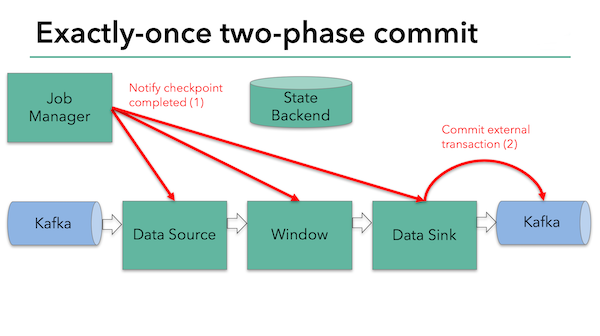
在checkpoint结束之后,JobManager会通知Listener们调用各自的Callback,此时Sink对象如果收到了JobManager发出的checkpointCompleted的通知,就知道所有的节点都准备好commit,然后此时才是真正的commit。
用法详解
简单来说,其实就是两步输出达到Exactly-once的思想,在很多地方都有用到。比如Hive在写表时,先将要写入的文件放入一个临时目录,然后再移入到target directory。
对应到程序里就4个步骤:
- beginTransaction - 开始这个事务,比如创建一个临时目录
- preCommit - 开始准备最后的commit,比如flush数据到临时目录中
- commit - 真正的提交数据,比如将临时目录下的数据移动到最终目录下
- abort - 删除临时目录
···
稍后我会写一个示例放出来
···