Disruptor是2011年由LMAX提出的一个无锁消息队列,在短短45分钟的视频分享中,有很多的信息可以分享和深究。
Background
我们先来看看多线程编程中各种”锁”带来的性能损耗有多大,以一个计数器为例:
static long counter = 0
private static void increment() {
for (long l = 0; l < 500000000L; l++) {
counter++;
}
}
我们以各种多线程常见的方式重新定义 counter,得到如下结果:
| 线程数 | 方案 | 损耗 |
|---|---|---|
| 1 | 无 | 300ms |
| 1 | 使用volatile修饰counter | 4700ms |
| 1 | 使用AtomicLong作为counter类型 | 5700ms |
| 1 | 使用lock给counter的操作加锁 | 10000ms |
| 2 | 使用AtomicLong作为counter类型 | 30000ms |
| 2 | 使用lock给counter的操作加锁 | 224000ms |
“锁”的性能损耗,有时候可以达到真正业务性能损耗的数倍甚至数百倍。而我们常用的消息队列如 ArrayListQueue,当有一个 Producer 和一个 Consumer时,它的消费场景如图所示:
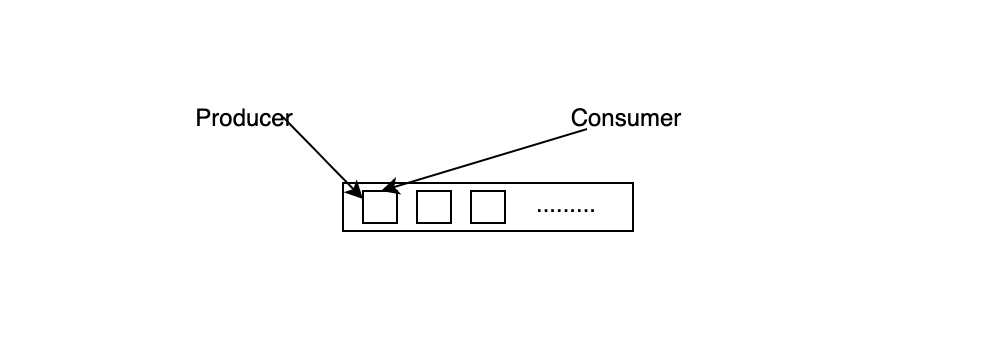
Producer 在往队列中添加数据,而 Consumer 在队列中获取并移除数据,两个线程同时改变消息队列的状态,这必然存在一个”锁”来保证生产者和消费者之间的一致性,而这个”锁”恰恰成为了使用队列经常遇到的性能瓶颈。这里存在着两个资源竞争:
- 数据的竞争,生产者需要添加,而消费者需要删除。
- 元数据的竞争,如剩余队列大小,最新数据索引等。
Contention Free Design
刚刚提到消费者改变状态的原因是因为需要把数据从队列中取走,那么,如果不需要取走,设置一个 cursor 来控制消费的位置,是否就可以避免带来性能损耗的”锁”呢?事实上 Disruptor 采用了 RingBuffer 的数据结构来存储数据,Producer 维护一个 Sequence 作为消息的索引,而 Consumer 维护自己的一个 index 来记录消费 RingBuffer 的位置。整体的结构图如下:
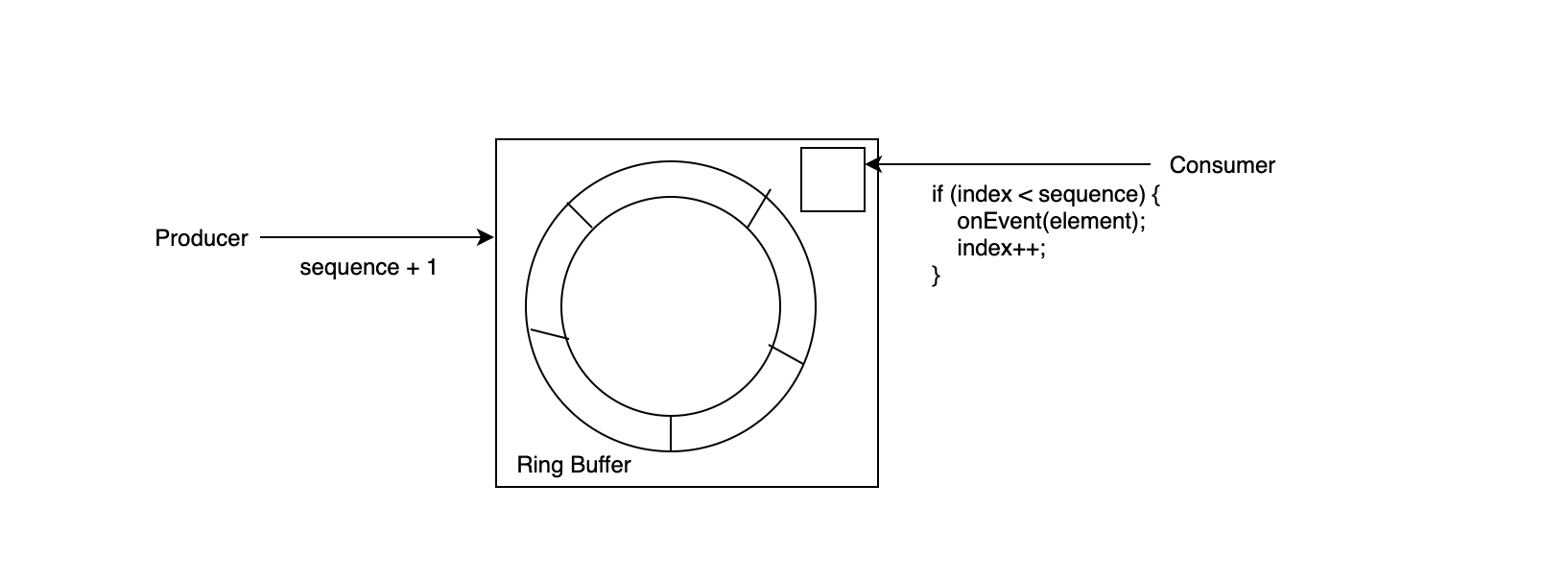
生产者和消费者唯一存在竞争的变量就是 sequence,因为消费者需要保证自己的 index 小于目前队列中最大的 sequence。那么为了方便,这个 sequence 变量自然可以使用 volatile 来修饰。但是有没有可能再进一步地去优化?
Optimization
如果想在 volatile 的层面上进一步优化,我们先要看看 volatile 为什么会让性能产生损耗。图中显示了一个多核CPU的架构图,这里需要提到,cpu 对指令的执行会有一系列的优化来达到充分利用 cpu 缓存的目的,比如 cpu 会将执行指令 pipeline 起来然后重排顺序,让缓存命中达到最大化。根据 jvm 的 happen-before 原则,volatile 的写操作必须要在读操作之前,也就是禁止指令的重排序,所以在对 volatile 进行变更后,系统会向 cpu 插入一条 Store Barrier,强制 cpu 将 Store Buffer 中的缓存数据写入到内存中去,而在读取 volatile 时,会插入一条 Load Barrier,强制 cpu 从内存中读取最新数据。Load Barrier 的操作相对来说,会比较重一些。
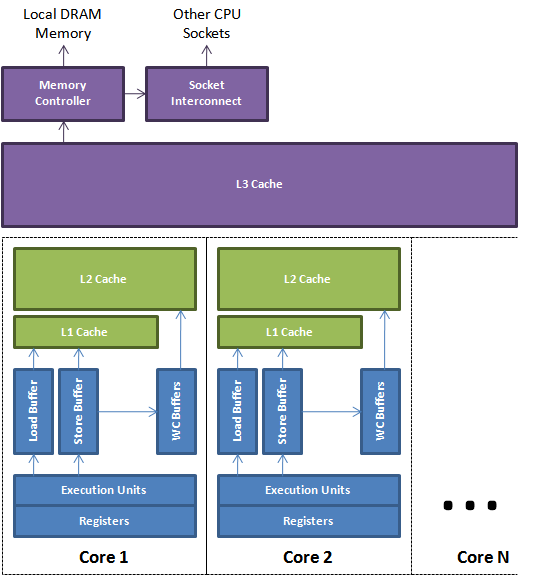
从消息队列的角度来讲,如果不是非常在意每次读取都要读取 sequence 的最新值,那么完全可以不需要禁止指令重排序,可以暂时直接读取缓存中的旧值即可,sequence 被更新之后,会向 cpu 插入 StoreStore Barrier,等待 cpu 自动刷新 Load Buffer 中的内容,这样的话,相当于每次都是从 cpu 缓存中读取数据。那么提供这种方式的代码就是 AtomicLong 中的 lazySet。