最通用的SQL解析框架 - Calcite
最近在研究Flink,在flink-table中看到了calcite,想到自己一年前刚刚从事大数据时,在Hive SQL就对SQL解析产生了很大的好奇,但当时对于这么多的概念一下子接受不过来就放弃了对calcite的研究,觉得现在还是应该再好好做一个总结。
背景
如果你经常做数据处理一类的工作,必定不会对SQL感到陌生。Calcite作为业内通用的SQL处理器,被广泛的运用在了Hive、Flink、Beam等顶级开源项目中。
过去不少博客中提到的SQL解析部分(如spark-catalyst)往往都是说到这样一个流程:
这个流程在Calcite中也是适用的,继续往下看。
速览
先看一段对SQL执行完整的一套代码。分为四个步骤:
- SQL解析
- SqlNode转换
- 优化
- 执行
// Convert query to SqlNode
String sql = "select price from transactions";
Config config = SqlParser.configBuilder().build();
SqlParser parser = SqlParser.create(sql, config);
SqlNode node = parser.parseQuery();
调用SqlParser将SQL语句生成SQL Tree。这部分是Java CC基于Parser.jj文件模板来实现的,输出为SqlNode的Tree的形式,并没有太多的代码,具体文档可见JavaCC Help。
// Convert SqlNode to RelNode
VolcanoPlanner planner = new VolcanoPlanner();
RexBuilder rexBuilder = createRexBuilder();
RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder);
SqlToRelConverter converter = new SqlToRelConverter(...);
RelRoot root = converter.convertQuery(node, false, true);
SqlToRelConverter将SQL Tree转化为Calcite中的RelNode。虽然两种Node都是类似于Tree的形式,但是表示的含义不同。SqlNode有很多种,既包括MIN、MAX这种表达式型的,也包括SELECT、JOIN这种关系型的,转化过程中,将这两种分离成RelNode关系型和RexNode表达式型。
// Optimize RelNode
RelNode optimized = planner.findBestExp();
基于Rule对RelNode做优化。Calcite中Planner分为两种,rule-based和cost-based,在后面将分析更复杂的cost-based的实现。
// Execute
Interpreter interpreter = new Interpreter(dataContext, optimized);
interpreter.enumerator();
在生成的optimized中,根据不同RelNode的类型执行不同的代码,如TableScan执行扫描Table的代码。
SqlNode转换
在SqlToRelConverter中,入口函数为convertQuery。
public RelRoot convertQuery(SqlNode query, final boolean needsValidation, final boolean top) {
if (needsValidation) {
query = validator.validate(query);
}
RelNode result = convertQueryRecursive(query, top, null).rel;
....
}
可以看出在convertQueryRecursive采取了遍历的方式来解析query,下面的一系列visit方法将SqlNode直接解析成了RexNode,方法截图如下: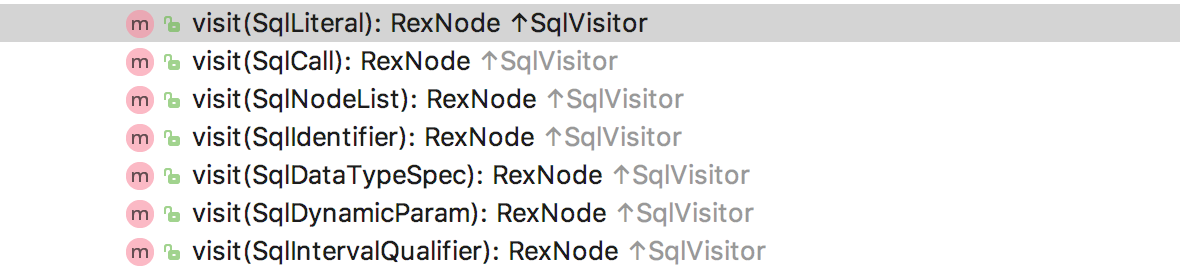
以visit(SqlLiteral)为例,根据不同的类型生成了不同的RexNode: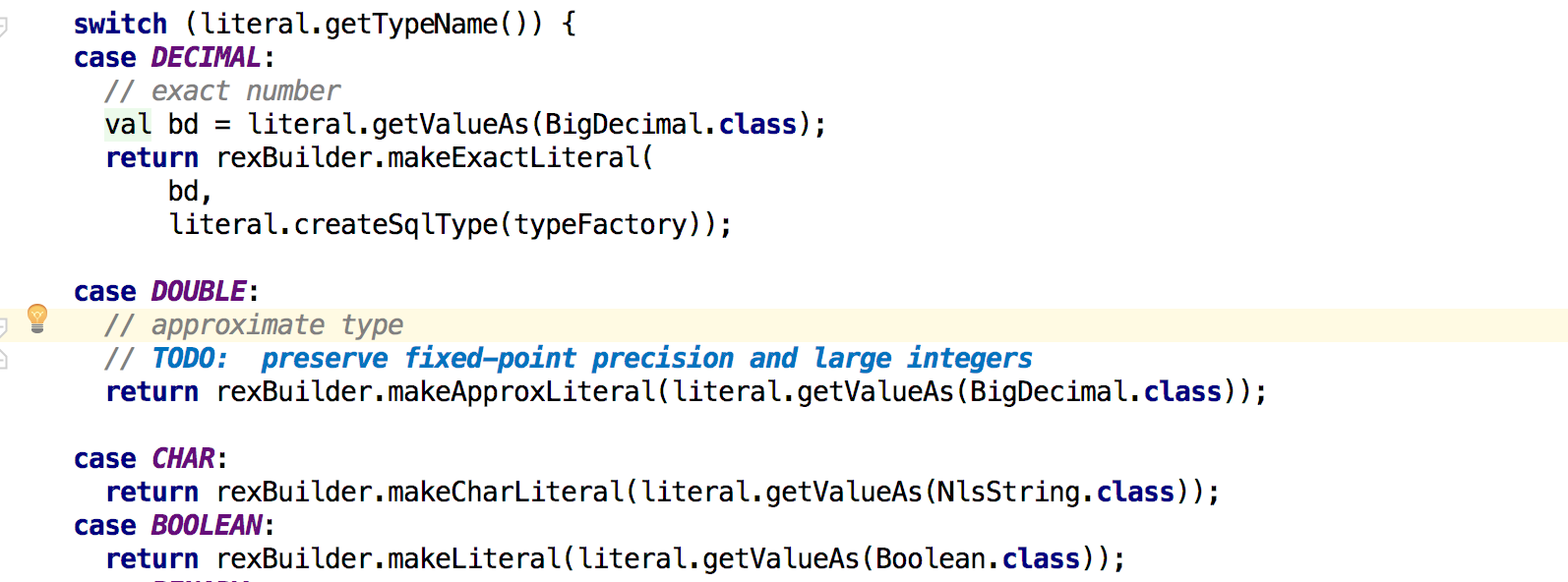
RexNode再根据不同的SqlNode.getKind()类型组合成不同的RelNode,例如Select -> Project。
优化
优化部分由Planner的findBestExp()执行,其中的策略分为很多种,使用者可以自定义。在calcite中提供了两种Planner:
- HepPlanner: 基于Rule对RelNode的Tree不断优化直到优化空间为0。
- VolcanoPlanner: 基于rule+cost采用随机梯度下降法优化,优化至每次优化空间都很小。
以VolcanoPlanner的优化逻辑为例:
- 注册RelNode,若发现符合Rule的RelNode,将新构建的RuleCall加入到ruleQueue中,等待后续过程进行优化。
- 进入优化环节,判断是否cost比上一次优化降低10%,是则继续优化,否则退出。
- 从ruleQueue中提取ruleCall进行优化。
- 重新构造RelRoot,更新cost。
- 进入2的循环。
- 退出。
其实采用VolcanoPlanner相对比较麻烦,因为要基于不同的存储来实现cost的计算,所以大部分大数据框架都是采取Rule-based的Planner形式。这部分的优化其实相对复杂,涉及到比较多的细节,如随机梯度下降的控制,循环次数的控制,内部RelNode的替换等逻辑,一个章节好像没有办法将这个Planner完全说明白,如果有兴趣的话,可以看看具体的实现VolcanoPlanner。
执行
执行根据不同的Node定义了代码的实现方法,从最底层的RelNode依次执行,采用source接收数据,sink发送数据。在Flink中,也有translate函数来做一个类似的实现。
Calcite源码相关名词释义
| 名称 | 解释 | 作用 |
|---|---|---|
| SqlNode | SqlTree中的Node | 在SqlToRelConverter中转化为RelNode |
| RexNode | 表达式 | RexLiteral是常量表达式,如”123”;RexCall是函数表达式,如cast(xx as xx) |
| RelNode | 关系表达式(动词) | 常在执行计划中看到,如Project,Join,Aggregate |
| RelSubset | 带有同一Trait的RelNode集合 | |
| RelSet | RelSubset集合 | |
| RelTrait | 特征 | RelNode对应的特征,如RelCollation可能是Project中的排序特征 |
| TraitDef | 特征定义 | 定义了Trait对应的一些方法 |
| Convention | 转化特征 | 用于转化RelNode,常见的有SparkConvention,FlinkConvention |
| Literal | 常量 | |
| Planner | SQL计划 | 可用于解析、优化、执行 |
| Program | 程序 | 可根据Rules自行构建,作用和Planner类似 |