本文聊聊 Flink 中的容错机制及其存在的常见问题,以及在生产实践中遇到的弱一致性场景和解决方案。
Global State
Apache Flink 中的 Checkpoint 机制借用了 Chandy-Lamport 算法的思想并做了一些性能上的改进(详见 Lightweight Asynchronous Snapshots for Distributed Dataflows )。
在上面的论文中,我们可以看到很多 Global State,从字面上看是全局快照的意思,但是在分布式系统中,该如何定义全局呢?理论上讲,全局状态就是各个节点在某一时刻状态的并集,而在分布式系统中,不同机器、不同节点的网络、负载、IO 甚至时间戳都有可能不同,我们并不可能做到真正意义上的“同一时刻获取所有节点的状态”。
Flink Checkpoint 机制
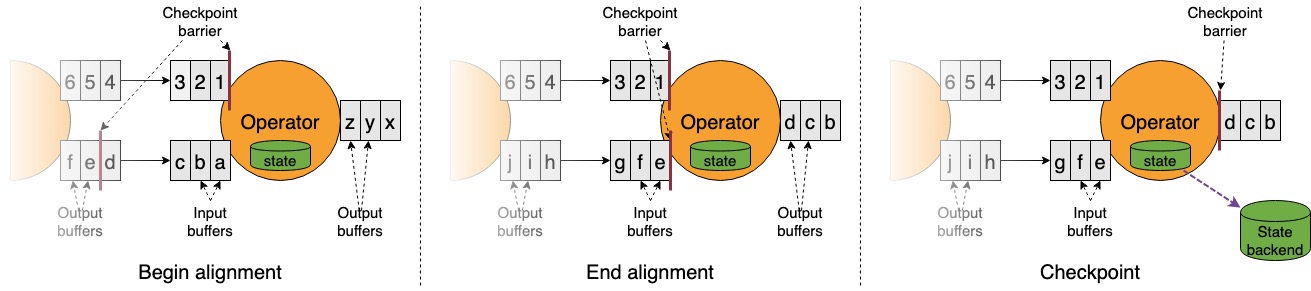
类似 Chandy-Lamport 算法中提到的 marker,Flink 中的容错机制基于 barrier 传递来实现,由 JobMaster 通过 Rpc 请求告知各个 Source Task 开始进行 checkpoint 流程,Source Task 在进行 checkpoint 的同时会向下游广播 barrier,各个 Task 在收到所有 barrier 后会各自进行当前节点的快照。
传输语义
传输语义分为两种:
- Flink 数据处理的语义,即 Flink 数据计算的语义(对应状态是处理算子的状态)
- 端到端的语义,即包含 Source 接收数据、Flink 数据计算、Sink 写入数据三个部分(对应状态是 Source、中间处理算子、Sink 的状态)
Exactly-Once
Exactly-Once:即一条输入数据只会影响一次输出结果,以统计事件个数的 count() 的任务为例,输入是 10 条,那么输出应该是 count=10。对应两种传输语义的底层机制是:
- Flink 数据处理:对于 Exactly-Once 的场景,如上图所示,Task 在收到第一个 barrier 时,会进入到 Begin Alignment 阶段。在这个阶段里,对于收到的 barrier 的上游 Task,会将数据缓存在 Buffer 池中,不进行消费;对于还未收到的 barrier 的上游 Task,会持续消费数据,直至集齐所有 barrier。这里保证了收集齐所有 barrier 做 snapshot 时,这个 Task 的状态是和 Source Task 的状态在时间点上是对齐的
端到端语义:端到端的 Exactly-Once,是通过 Two-Phase-Commit(两阶段提交)来实现。除了上面提到的处理算子的 Exactly-Once,对于 Source 和 Sink,两阶段提交流程如下所示:
- Begin Transaction:开启一个新事务,每次 checkpoint 可以看做是一次事务的提交,所以两次 cp 之间是一个完整的事务
- Pre commit:Source/Sink 进行 snapshot 时,进行事务的 pre-commit 操作
- commit:JobMaster 发送 notify 回调时,进行事务的 commit 操作
- abort:如果失败,进行 abort
At-Least-Once
At-Least-Once:即一条输入数据会影响多次输出结果,以统计事件个数的 count() 任务为例,输入是 10 条,那么输出可能会出现 count>10。对应两种传输语义的底层机制是:
- Flink 数据处理:Flink 内部对于 At-Least-Once 的场景,与 Exacly-Once 场景的区别是,Task 在收到 barrier 后,仍可以对收到的 barrier 的上游 Task 数据进行消费。举例说明,假如在 Kafka Source(index=1)在 offset=100 时下发的 barrier,此时下游 Task 的状态聚合值 count=100,如果下游 Task 收到此 barrier 后,仍继续消费此 Source Task 的数据,那么等集齐 barriers 后的快照,对应的状态聚合值 count>100;如果此时作业发生 failover,Source Task(index=1) 会从 offset=100 恢复,而下游 Task 会从 count>100 恢复,此时出现了数据重复。
- 端到端语义:端到端 Exactly-Once 的要求是 Source 和 Sink 需要支持事务机制。事务机制对于 OLTP 中的组件很常见,但在大数据计算场景下,不管是 Kafka,还是其他 AP 存储,目前都对事务机制没有太好的支持。基于当前现实情况,大部分对数据准确性有严格要求的业务,通常使用 Flink 数据处理的 Exactly-Once + 支持幂等的下游组件来完成近似的端到端 Exactly-Once。
弱一致性快照
强一致性快照机制通过 barrier 巧妙地将分布式系统中各个 Task 的快照进行对齐。但是这种强一致性快照中的一致性保证,在真实情况中往往是一种 trade-off。
弱一致性快照出现的背景
上面提到了两种端到端传输语义,其中 Exactly-Once 的实际应用难度较大,需要上下游支持事务机制(大流量场景下开启事务可能会产生性能衰退);At-Least-Once 会产生数据重复,或者需要下游支持幂等写入才能达到 Exactly-Once 的效果。
除此之外,还有一种语义是 At-Most-Once,就是不保证数据一定能够被处理。当然用户如果不开 Checkpoint,就近似等于 At-Most-Once 的实现,不过这样的操作在长周期窗口的业务逻辑中,就会丢掉过多的数据,也是用户无法忍受的。
这里以三个场景为例:
- 场景一:将原始的行为数据转发到下游不同消费者各自的 Kafka。下游消费可不想处理重复数据这种棘手的事情(做过实时数仓的同学应该都了解在实时场景做去重是一件多麻烦的事),从下游的角度来看,更加期望接收完全准确的数据,即 Exactly-Once 的传输语义,但在实际能力做不到的情况下,期望少丢也少重,尽量减少后期数据建模带来的准确性问题
- 场景二:将特征和用户行为拼接成模型需要的正例/负例喂给下游的模型训练任务。对于实时模型,数据重复和数据丢失会造成不同的影响,过多的重复数据会导致模型训偏,过多的数据丢失会导致模型训的不够充分,在做不到 Exactly-Once 的情况下,这类场景也是期望做到少丢少重。
- 场景三:统计视频访问量展现给创作者。这类指标通常使用 Lambda 架构,实时计算出一个”大概”的数据,离线进行 T+1 修正,但是从创作者的角度考虑,产生大量重复会直接影响创作者对于收益的判断,所以这类场景同样期望少丢少重(重复的代价 > 丢数的代价,因为 T+1 修正后对于创作者而言一个是收益少了,一个是收益多了)。
这类场景的特点都是容忍数据丢失,但是既不允许丢太多,也不允许重复太多。而反过来看目前的 Checkpoint 机制,在数据量较大场景下,会有如下问题:
- 数据重放问题:由于 checkpoint 的间隔设置成分钟级别,一旦有 checkpoint 失败,就会出现几分钟的数据重放,如果碰到环境不稳定的情况,连续几次 checkpoint 失败,重复数据的量级就会比较大
- Checkpoint 成功率问题:强一致性快照机制中,单个 Task snapshot 失败会造成全局快照失败,所以 Checkpoint 成功率约等于 Math.pow(单个 Task 成功率, Task 个数),数据量较大,Task 较多的情况下,环境抖动造成的 Checkpoint 失败概率大大增加
- 性能问题:将 Flink 数据处理语义设置成 Exactly-Once 后,如果出现数据倾斜(轻微),在 Alignment 阶段会造成上游反压,导致大部分 Task 会在一小段时间里出现空置的情况,所以我们是可以观察到 CPU 利用率会随着 Checkpoint 的间隔发生有规律的抖动。目前社区的优化基本上是采用 trade-off 的形式来减少 cp 的时间开销(这种 trade-off 也未必一定是合适的),比如
- FLIP-76 Unaligned Checkpoint(空间换时间)
- FLIP-158 Generalized Incremental Checkpoints(IO 资源换时间)
在强一致性的限制下,所有的算子都要“共同进退”,比如快照必须同时成功,failover 必须同时发生(相连接的算子)。显然,在这种 Checkpoint 机制下做到数据”少重”是很难的。综合以上考虑,我们很容易进入这样的思考,如果在达不到理想的端到端 Exactly-Once 传输语义情况下,对于允许少丢少重这部分场景,我们是否可以选择“少丢”来作为技术架构上的目标?技术方案层面上,是否可以放弃已有的强一致性快照,通过牺牲一致性的代价来换取性能、稳定性、以及避免数据重放等收益?
弱一致性快照思路
从强一致性到弱一致性,不单单是传输语义从 Exactly-Once 到 At-Most-Once 的变化,它更多是通过一致性的退化来换取更多的灵活性,但同时也意味着它要解决强一致性面临的问题。
在强一致性快照中,我们使用 barrier 作为时刻的物理载体来保证各个节点快照的一致性,那么在弱一致性快照中我们就可以将 barrier 去掉。想象一下我们的快照机制变成这样:
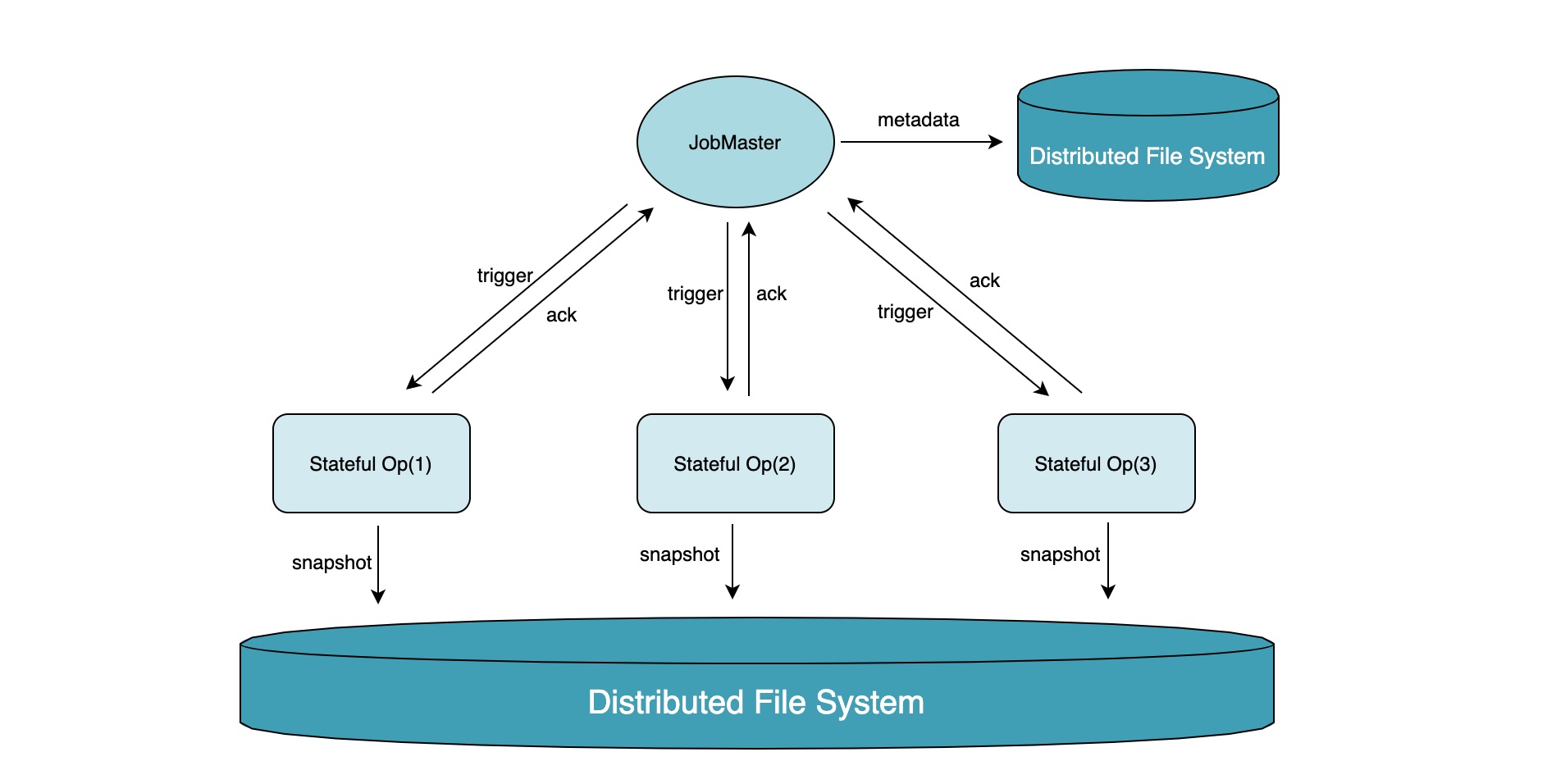
经过简化,JobMaster 直接 trigger 有状态算子(非 Source)进行快照触发,后续的步骤和 Flink 原生的 Checkpoint 机制类似,Task 制作快照完成后通过 Rpc 向 JobMaster 发送 ack,JobMaster 将此次 checkpoint 元信息记录在分布式文件系统上。
通过对 barrier 的简化,我们可以将 barrier 的对齐问题解决掉,但同时我们需要考虑一个新的问题,即如何尽可能地少丢数据? 解决思路可以拆解为两个部分:
- 减少单个算子丢数据的量:由于弱一致性快照中不对 Source 算子进行快照,所以单个算子丢数据的量约等于算子失败到上次 CP 成功的时间间隔内 Source 发送到该算子的数据量,我们可以通过减小 CP 间隔以及增大 CP 成功率来做一些改善
- 减少丢数据的算子个数:强一致性快照中为了保证各个算子之间的一致性,如果出现了 failover,那么所有算子都需要发生重启;但在弱一致性场景中,不再需要对各个算子之间做一致性保证,所以我们可以不必使用全局重启的策略
实现难点
虽然弱一致性快照机制做了很大的简化,但要做到较完备的程度还是比较困难的,比如:
- 流式计算中的数据,很多时候会发生互相关联的情况,比如某条 Record 是窗口触发的条件,如果这条数据发生丢失,那窗口可能永远不会触发(对于下游来说,相当于丢弃了整个窗口的数据)
- 部分算子的实现利用了 Timer、Event 等机制,如何与这些机制做兼容?
- 如何设计 DAG 中单个 Task 出现 failover 不影响相邻 Task 的策略,当然,这一功能在 Flink 社区中的 FLIP-135 中已经有所涉及(同样是针对上面提到的模型训练的相关场景)
- 如何解决单个算子快照失败影响其他算子快照的问题。在弱一致性快照机制中,各个算子相互独立,此时理论上并不需要所有算子同时快照成功,但是在允许部分算子快照失败的情况下,如何做到快照恢复上的兼容,以及 JobMaster 如何与各个 Task 进行交互?
实际的生产应用中,是比较容易做到对固定执行模式的支持(比如 map-only 作业或者双流 Join 作业),但如果要针对所有类型的算子和 DAG 完成改造,那应该是一个比较彻底的重构了。
总结
本文主要介绍了 Flink 中的容错机制和传输语义的关系,并且指出在部分的实际应用场景中,强一致性的快照机制未必能够满足生产需求,此时通过放弃一致性,使用弱一致性快照机制来获取更好的灵活性或许是更好的办法;并根据实际生产应用的经验,提出了弱一致性快照的解决思路以及实施你难点。