Flink 中 Network Buffer 相关知识。
问题
如果你是带着以下问题来到这里的,那么我相信这篇文章可以给你答案。
- Network Buffer、或者 Network Segment 的作用是什么?在很多地方看到这个名词但是不知道是做什么用的
- Network Buffer 占用的内存是哪一块?应该如何去调整这一块内存?
- 为什么每次扩大并发后重启,就会报出
insufficient number of network buffers的错误?为什么复杂的拓扑需要的 network buffers 会这么大?network buffers 的数量应该如何计算? - 如何合理地设置 network buffers 的数量?
用途
Network Buffer,顾名思义,就是在网络传输中使用到的 Buffer(实际非网络传输也会用到)。了解 Flink 网络栈的同学应该会比较清楚,Flink 经过网络传输的上下游 Task 的设计会比较类似生产者 - 消费者模型。如果没有这个缓冲区,那么生产者或消费者会消耗大量时间在等待下游拿数据和上游发数据的环节上。加上这个缓冲区,生产者和消费者解耦开,任何一方短时间内的抖动理论上对另一方的数据处理都不会产生太大影响。
这是对于单进程内生产者-消费者模型的一个图示,事实上,如果两个 Task 在同一个 TaskManager 内,那么使用的就是上述模型,那么对于不同 TM 内、或者需要跨网络传输的 TM 之间,是如何利用生产者-消费者模型来进行数据传输的呢?
如果之前看过 credit-based 机制介绍 的同学可能对接收端的 buffer 池会比较了解,我们将发送端和接收端结合起来看看,
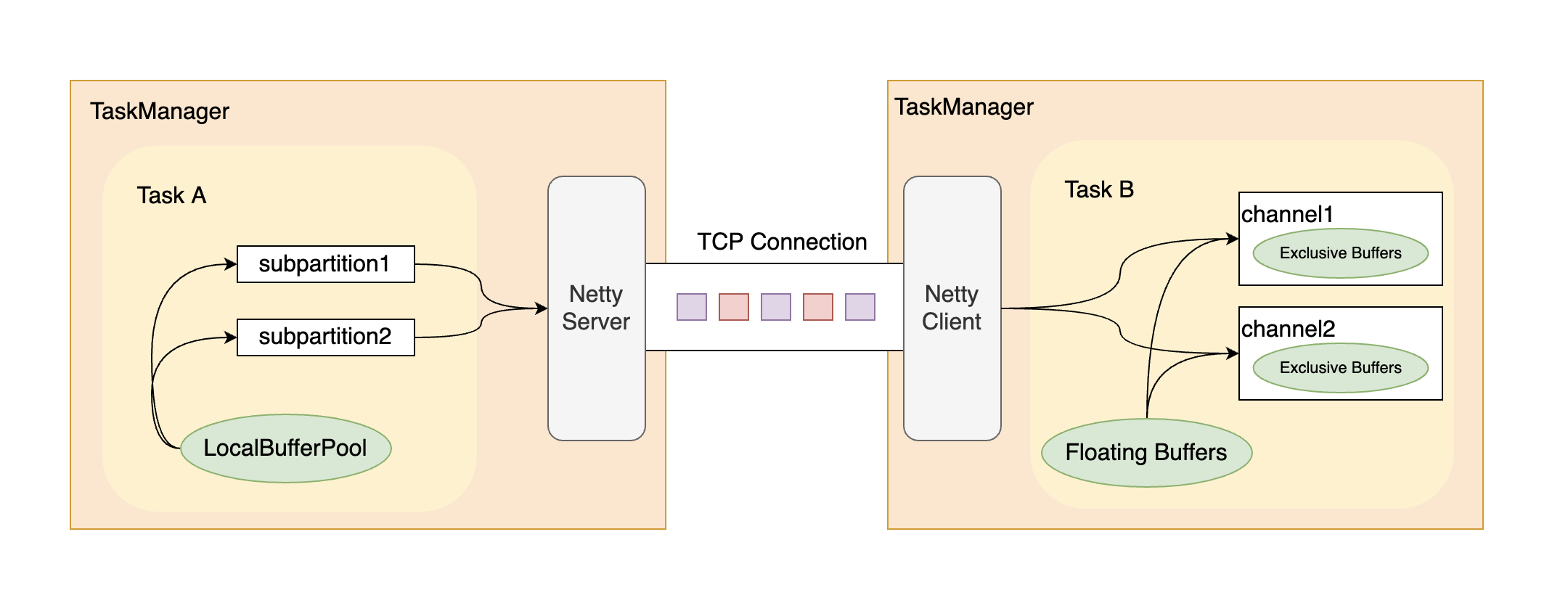
可以看到,在 Netty Server 端,buffer 只存在 LocalBufferPool 中,subpartition 自己并没有缓存 buffer 或者独享一部分 buffer(这样的问题我在 Flink网络栈中反压机制的优化 中有提到过),而在接收端,channel 有自己独享的一部分 buffer(Exclusive Buffers),也有一部分共享的 buffer(Floating Buffers),所以,Network Buffer 的使用同时存在于发送端和接收端。
由此可见,TaskManager 内需要的 buffers 数量等于这个 TaskManager 内的所有 Task 中的发送端和接收端使用到的 network buffer 总和。明确了 Network Buffer 使用的位置,我们可以结合一些参数计算出作业实际所需的 Network Buffer 数量,具体计算方法看下面。
使用
内存计算
不少同学不太明白 UI 里 TaskManager 中的 Network Segments,先举例来看看这个 Network Segment 是如何计算的,以 1.9 为例,我们先来看几个参数:
| 参数 | 含义 | 默认值 |
|---|---|---|
| containerized.heap-cutoff-ratio | JVM cut-off 部分使用的内存 | 0.25 |
| taskmanager.network.memory.fraction | Network Buffer 使用的内存 | 0.1 |
| taskmanager.memory.segment-size | Network Buffer 的大小 | 32kb |
不同版本中的参数名称和默认值可能不一致,以上述默认参数为例,假如我们有一个 2g 的 TaskManager,那么各部分对应的内存数值为:
- JVM cut-off 内存 = 2g *
containerized.heap-cutoff-ratio - JVM heap 内存 = (2g -
JVM cut-off 内存) * (1 -taskmanager.network.memory.fraction) - JVM non-heap 内存 = 2g - JVM heap 内存
- Network Buffer 内存 = (2g -
JVM cut-off 内存) *taskmanager.network.memory.fraction - Network Segments 个数 =
Network Buffer 内存/taskmanager.memory.segment-size
其中,JVM cut-off 内存和 Network Buffer 内存都会以 Direct Memory 的形式存在。计算得到的 Network Segements 个数会存放到 TaskManager 管理的 NetworkBufferPool 中,Task 中使用的 Network Buffer 都需要先向 NetworkBufferPool 进行申请,如果无法申请到,就会出现 insufficient number of network buffers 的错误。
既然总的 Network Buffers 数量有了,那么实际需要的 Network Buffer 该如何计算呢?拆成发送端和接收端两部分来看:
- 发送端共享一个 LocalBufferPool,总大小为 subpartitions + 1,subpartition 是这个 task 数据流向下游 task 的通道,如果和下游连接方式是 HASH 或者 REBALANCE,那么 subpartition 数量为下游 Task 数。
- 接收端的 Network Buffer 数量 = channel数 *
taskmanager.network.memory.buffers-per-channel+taskmanager.network.memory.floating-buffers-per-gate,channel 数是接收上游数据的通道,如果和下游连接方式是 HASH 或者 REBALANCE,那么 channels 数量为上游 Task 数。
| 参数 | 含义 | 默认值 |
|---|---|---|
| taskmanager.network.memory.buffers-per-channel | 每个 channel 独享的 buffer 数 | 2 |
| taskmanager.network.memory.floating-buffers-per-gate | Floating Buffer 数量 | 8 |
将 TaskManager 上所有 Task 的 Network Buffer 数相加,即可得到 TaskManager 内实际需要的 Network Buffer 数量。而实际上,面对一些复杂的拓扑,并行度不一致的拓扑,我们在不清楚调度细节的情况下,无法准确计算得到这个数值,唯一的办法就是经验估计,调整上述的一些参数。
指标监控
Network Buffer 还有一个好处就是可以用来做反压的监控,虽然 Flink UI 上提供了反压监控的工具,但是企业内部在构建监测看板时并不能方便地直接去使用,而 Flink 自身提供了很多 Network Buffer 相关的指标,其中最常用的如下:
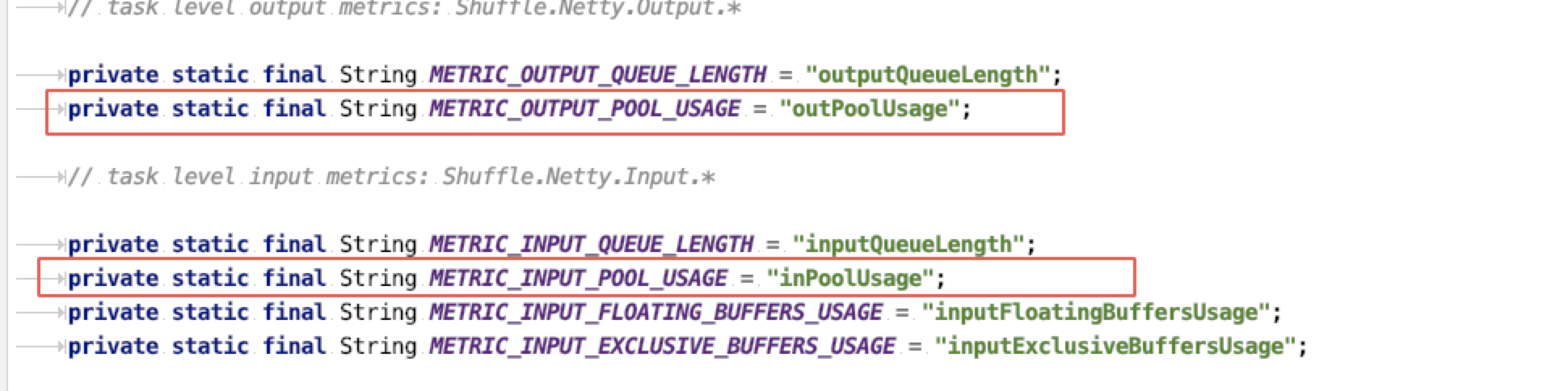
其中 outPoolUsage 是发送端使用的 Buffer 数占 LocalBufferPool 的比例,inPoolUsage 是接收端 Buffer 数占总的 Buffer 数(exclusive + floating)的比例。(如果是 Local 传输 inPoolUsage 是不会显示出来的)
将这些指标放在看板里,可以很清晰地知道,从哪个 Task 开始反压并定位到对应的 host 和 TaskManager。
遗留问题
前面提到对于复杂拓扑,network buffer 数量无法计算的问题,但其实在拓扑构建后,每个 Task 对应的 network buffer 已经可以根据已有的参数计算得到,在分配资源后,每个 TaskManager 中的 Task 的布局也可以知道,所以理论上讲,network buffer 的设定是可以根据 DAG 来计算得到的,让用户对此无感知,而不是等到 Task 启动后,实际分配时再报错告知用户。