记录一下自己读的Paper。
模型结构
- 2025.06 by NVIDIA
- Eagle-2: https://github.com/NVlabs/Eagle
- GR00T: https://github.com/NVIDIA/Isaac-GR00T.git (找
class Gr00tN1d6(PreTrainedModel)),以 Eagle-2 作为 backbone,后面加了一个 ActionHead 模型结构,Flow Matching model;

RoboBrain 2.5: Depth in Sight, Time in Mind.
- 近期更新 by 北京智源研究院,基于 Qwen-VL 上做的,
- 这是模型的 config, model.config,推理的代码是 https://github.com/FlagOpen/RoboBrain2.5/blob/main/inference.py,但是完全是基于 Qwen 的 architecture 来训练的;如果模型结构没有什么特点,那主要区别就是数据上?
- paper 里说的优势是 1) Precise 3D reasoning 2) Dense Temporal Value Estimation,没看到代码是怎么做的;
- 一年多前提出的,By Standford
- 7B model, Open X-Embodiement dataset,放到现在来看好像没什么太多特别的点?跟 UniVLA 好像很类似。
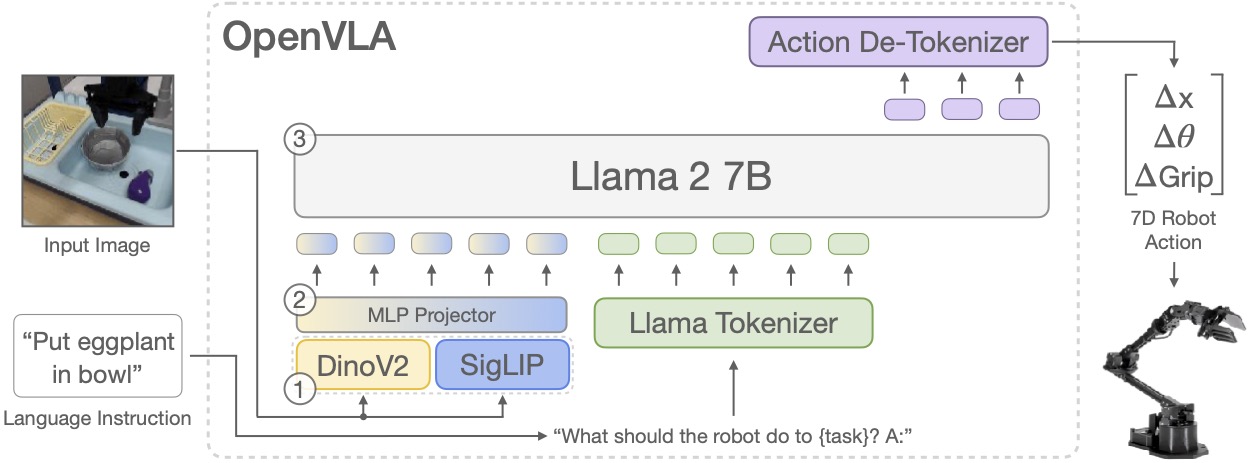
We train OpenVLA by fine-tuning a pretrained Prismatic-7B VLM. Our model consists of three key elements:
(1) a fused visual encoder, consisting of a SigLIP and a DinoV2 backbone, that maps image inputs to a number of ``image patch embeddings'',
(2) a projector that takes the output embeddings of the visual encoder and maps them into the input space of a large language model, and
(3) a Llama 2 7B language model backbone that predicts tokenized output actions.
These tokens get decoded into continuous output actions that can be directly executed on the robot.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
- By NVIDIA,核心是提出了 motion tracking 这个概念,解决了单一 model/policy/reward 的定制化 RL;
- 和 GR00T model(VLA) 配合,有点像 Helix,分大小脑的概念;
- 后续再仔细看看,
- 25 年中发的,互联网数据做 pretrain (VLA),机器人实操数据做 post-train(VLM)
- github: https://github.com/Physical-Intelligence/openpi
- 过了一下
pi0.py,训练的compute_loss是用的 flow matching,围绕公式x_t = time_expanded * noise + (1 - time_expanded) * actions,随机加噪声,然后比较action_out_proj预测的 v_t 和实际的 u_t 差值作为 loss;推理就是反过来,根据 noise 通过 ODE 不断的解析出实际的 action;
- 过了一下
- 比较核心的 model 是 PaliGemma,其他的都是线性 model 做一下维度的转换;会先把 action_dim 转到 action_expert_config,经过 mlp 转回 action_dim;
- action_dim = 机器人动作空间维度(数据/任务侧)
- action_expert = 一个 300M 的 Gemma 子网络,其 width = 1024(模型结构侧)
- 这个 expert 层也有些特别,和别的直接基于 latent action space 做预测的不一样
- cross-embodiment training,如何 combine 不同格式的 embediment data?

GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
- 24.10 seed 发的
- 基本没什么细节
- world model, 24年 google deepmind,现在 Genie3 也特别火了,很有意思
- 特点:
- 只用了 video 来训练,unsupervised learning,action labeling 也依靠 video frames 来推断
- 跟机器人的关系,在 RT1 model 的训练里,把 action 数据丢掉,仅仅用机器人的视频数据就训出来了 consisten action latent,frame(n) -> latent space -> frame(n+1),如果这个可以泛化,那么机器人的 latent 完全可以从 world model 里出?
- 模型结构
- latent action model: 和上面机器人类似,给定 latent action codebook = 8,VQ-VAE;这里的主要目的是为了实现 labeling 产生 latent action 进入下面的训练,实际推理的时候是没用的;
- video tokenizer:单独训练,VQ-VAE(怎么训的?),latent z 包含了 1:t 的视频信息
- 主体 model: z(1:T-1) + a(1:T-1) 作为 input, frame(T)作为 output 和视频 ground truth 比较
- 推理时,video token + 用户的 action(现在只能前后左右),来做 next frame prediction
- 26.1.29 Helix02
- System 2 (S2) reasons slowly about goals: interpreting scenes, understanding language, and sequencing behaviors. (7B 模型)
- System 1 (S1) thinks fast, translating perception into full‑body joint targets at 200 Hz. (80M 模型)
- 从 S2 的 latent space 上加 transformer 算出来的;(动作空间是多少?)
- System 0 (S0) executes at 1 kHz, handling balance, contact, and coordination across the entire body. Together, they form a tightly integrated hierarchy from pixels to torque. (10M 模型)
- 这里有点没太看懂 S0 的作用?coordination 不也是 joints 的动作集合的结果?为什么不和 S1 放在一起呢?
- 资料有点太少了,
- 26.1.29 宇树开源,基于 Qwen-VL-7B 开源模型做的 fine-tune,340h 真机数据;
- 代码看了下很奇怪,比如 dataloader 里 torch 结构套 tensorflow 结构......
- 26.1 蚂蚁开源,20,000 hours training data, data scaling law,
- Observation 来源于 3 个角度的 image + Task Instruction + robot state
- 用 Flow Matching 的思路来 train,让预测动作逼近真实的 action
- 用一个 Project Layer 来让 3 个 Image 的输入能够输出正确的 depth(基于 LingBot-Depth 模型的结果)
- 关于模型这部分讲的太少了;架构优化这里也只讲了 HSDP 和 fusion 优化;没干货???
- github 看了下 evaluation 部分也有点水。。
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
- 26.1.22 提的,nvidia cosmos,看了比较久才看明白,
- 用的是基于 transformer 的扩散模型,有两个特点:
- 这里用了 cosmos-predict2 的 world model(视频扩散模型),利用上了世界理解能力
- (潜在帧注入:整合新模态)没有任何的模型结构变化,直接把机器人的相关数据(如 state,action,value func)直接注入到 latent space
- 这样做的好处其实是适用于任何类型的机器人数据集,模型的泛化性看起来很好。

- 1.7 清华提的,把 video 和 robot trajectory 通过 codebook align 起来。
- 整体看起来挺理论的,感觉不行
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
- 25.6 月 Meta 发的,对多模态的表征
- 有空再看看细节,从 Action100M 看过来的;
Flow Matching for Generative Modeling
- 23 年发的,看到 Qwen 的多模特征是基于 FM 来做的,用 GPT 学了下
- 可以类比成无限层的 transformer (continous transformer)
- 在多模里相比于 diffusion model, 因为 diffusion 在 token 上加噪,会导致 token 语义发生破坏(而在图片上加噪,反而没这个问题)
- 不再有各种 encoder,前置到统一的 tokenizer
- 这里在公式上和 diffusion model 的区别是: 1) 公式上 FM 是简单线性的, diffusion 的公式要更加复杂 2) 模型的预测目标 FM 是求导算 velocity,
x_t = t*noise + (1-t)*action;v_t(dx_t/dt) = noise - action; loss = model(action,noise,ts) - v_t,diffussion 是人为加噪声和模型预测的噪声做对比loss = (noise - noise_pred)
Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
- from Feifei Li Lab, PointWorld 相关
- 从用户的任务描述,转换成 3DFlow 运动轨迹,再给 robot 去执行,解耦了机器人形态和任务本身强绑定的限制;
- 不过如何从 2D 视频到 3D 运动轨迹,这块是比较有技术含量,开源之后要看一下源码实现。
mHC: Manifold-Constrained Hyper-Connections
- 2025.12.31 25 年年底,deepseek 发的
- 主要背景是当前 transformer 网络里的 residual/Hyper Connection 网络结构里,直接把输入加回到输出的做法,经过多层 layer 的叠加后,会出现梯度爆炸或训练不稳定的情况。
- mHC 的做法是让 HC 里的可学习矩阵,通过正交的一些手段,强行让他们“范数守恒"(总长度不变,但是可以旋转和转换),让这些可学习矩阵不会随着 layer 增多而出现不可控的情况。

Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
- 24 年 ACL,video-based conservaiton model
- 除了模型之外,做了一个数据集和 benchmark,https://github.com/mbzuai-oryx/Video-ChatGPT?tab=readme-ov-file
- 模型结构主要是增加了 CLIP ViT-L/14,把视频拆成 Spatial 和 Temporal(空间和时间),空间上根据 patch_size 拆成 N 个 token,时间上用 T 个 frame 标识,经过 pooling 后映射到语言空间;
- 数据生成,分人工标注和半自动化标注
- 人工标注:数据来自于 ActivityNet-200,人工再丰富了一下描述
- 半自动化标注:
- 关键帧:The BLIP-2 imagecaptioning model generates frame-level captions,
- 关键帧描述:GRiT dense captioning model provides detailed captions for scene objects.
- 标签:Tag2Text,remove noise
- 再结合 GPT-3.5 进行内容丰富

Unified Vision-Language-Action Model
- 25 年 6 月发的
- 基于智谱的 Emu3 pre-train model,主要特点是 language/vision/action 在统一的 token 空间(不同的 tokenizer 但是在同一个 token space)下,用自回归 transformer 结构来做 prediction。
- 利用了大量的 video data,用 FAST tokenizer(by Physical Intelligence)
- 和其他常见 VLA model 差别:VLA 通常是 vision->language->action,至少 2-stage 的训练,action 有可能被 semantics space 限制;
- 训练分两部分
- post-train(不包括 action): 训 Lt(用户 task 描述) + Lv(初始vision) -> Lv(t+1),Lv(t+2)...
- fine-tune: 加上 action

PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
- 核心概念是给一个 robot 描述(URDF) + RGB 图片,然后能推断出后续所有的运动轨迹,
- 3D point flow 表示环境和 robot action,
- real-time(0.1s) inference speed,某些场景无需 post-training
- dataset 基于 DROID 再经过下面的 annotation pipeline
- 训练时,去除噪音,通过pixel 级别的 weight
- annotation pipeline:
- Foundation-Stereo 产出 pixel 级别的 depth(30cm-80cm 比较好)
- VGGT(Visual Geometry Grounded Transformer) 产出 global pose(camera 和 robot 相对位置,(R,t),角度和距离矩阵来描述)
- CoTracker3 产出 pixel 在未来时间线的 trajectory
数据集
- 25.3 发布 by AgiBot,主要亮点是 硬件平台 + 采集的数据比较丰富, high-quality; 1M+ Trajectories, 由于这家公司主要是做数据的,忽略 GO-1 model;
- 收集数据的时候有个 failure recovery 操作,如果遥操人员失误,会人工标记这些片段给后续模型学习,占比 1%;

Action100M: A Large-scale Video Action Dataset
-
Meta 26.1.15 发布的, https://github.com/facebookresearch/Action100M
-
自动化 pipeline 实现的,这个有点厉害。1.2M youtube videos,
-
Action100M is generated by a fully automated pipeline that
- 分段:(i) performs hierarchical temporal segmentation using V-JEPA 2 embeddings,
- 打标 caption: (ii) produces multi-level frame and segment captions organized as a Tree-of-Captions,
- 整合: (iii) aggregates evidence with a reasoning model (GPT-OSS-120B) under a multi-round Self-Refine procedure to output structured annotations (brief/detailed action, actor, brief/detailed caption).
-
Data Pipeline
- 分段:window_size=64,step=8,所以每个 window 有很多重复的 frame,但是会有不同的 representation,这里把他们的表征不断 acc(不知道这个 acc 过程是怎么做的?),形成最后唯一的 emb。visual token 来源于 V-JPEA2(基于 ViT)。另一个点是采用了分层法,会存在不同级别的段落,长的,短的,数据示例:https://github.com/facebookresearch/Action100M/blob/main/data/hySSAAw4t24.json
- 打标:有两个模式,对于每个 segment, 1) Llama 打标 mid frame 2) Perception-LM-3B 打标 video(video 由 segement 里 32 个 frame 组成),这里用的 3B model 也是 Meta 的,用来理解视频生成 caption/question/descriptions..
- 整合,用的 GPT-OSS-120B model,we generate structured action annotations by prompting GPT-OSS-120B5 to extract five fields of information: brief action description, detailed action description, actor, brief video caption, and detailed video caption.
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models
- 25.8 发布的,感觉和其他评测框架没有本质区别
- 跟着命令过了一遍代码链路,
uv run python run.py --model Qwen3-VL-2B-Instruct --data COCO_VAL
- 2025.12.22 李飞飞实验室发的 benchmark,用于评测 VLM,基本所有模型都”不及格“(落后于人类认知水平)
- 最后他们产出一个有意思的观点,
when estimating kinematic quantities, existing VLMs hallucinate by relying heavily on pre-trained world knowledge while hardly inferring from the actual reference video and text.
- 最后他们产出一个有意思的观点,
- 这里有个不一样的点,之前大部分的 benchmark 使用的是 VQA 的模式来让 model 描述或者做选择题,但是这个 benchmark 主要会考察模型是否真正能理解视频以及用物理学知识来解决一些具体的问题。(因为能描述可能是因为记忆,但不一定能理解和使用)
- 数据集上有这几类:
- 2D/3D:主要区别是景深(depth)
- Static/Dynamic:举个例子,static 是求长度(不变的),dynamic 是求速度(某个时间点 t 的数值);
- 数据上会提供 Prior(先验知识),和数学问题,和标准答案;
- 数据集来源
- Blender Simulation: Blender 是一个研究用的仿真软件
- Lab Capturing: 实验室采集
- Internet: 互联网上扒数据
- Key Findings
- VLMs rely more on learned prior knowledge than visual inputs for physical reasoning.
- 把 video 撤掉,仅保留问题和prior,模型也能答
- VLMs (mostly) do not reason but memorize
- 把 prior 先验知识的数值乘上一个 factor,发生了量级上的改变,但是结果没有发生太大变化,模型还是以真实世界的结果来返回,
- VLMs rely more on learned prior knowledge than visual inputs for physical reasoning.

ALOHA(A Low-cost Open-source Hardware Arm)
- 双臂操作数据集,解决真实世界双臂 robot 数据少的问题;
- Task 很多样,fold cloth, open container...
DROID(Distributed Robot Interaction Dataset)
- standford 出的数据集,数据比较多,76k episods,
- 有个 visualization
Calvin(Composing Actions from Language and Vision)
- 22 年提的,通过 language 完成 long horizon task,
We present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites.·
- 23 年提出,场景宽度上比较多,可以无限生成 manipulation task
Label
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
- MIT x NVIDIA 25 年底发的,标注框架,主要特点是理解 spatial movement
- 处理流程
- video preprocess: 把视频拆成 segment,计算 motion score(VGGT),如果过大就丢弃(camera 移动过快会造成追踪效率低)
- object detection:
- open-vocabulary(通用的物品) : Qwen2.5-VL-7B 识别 object,Grounded-DINO 来定位 object
- human-centric(人手): person-detection(Cascade Mask R-CNN) -> body keypoints(ViTPose+) -> hands(Hands23) , 有点复杂
- Temporal Tracking: 每 5frame 用 SAM2 来 tracking
- Caption Generation: GPT-4o-mini by prompt
- same as caption
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
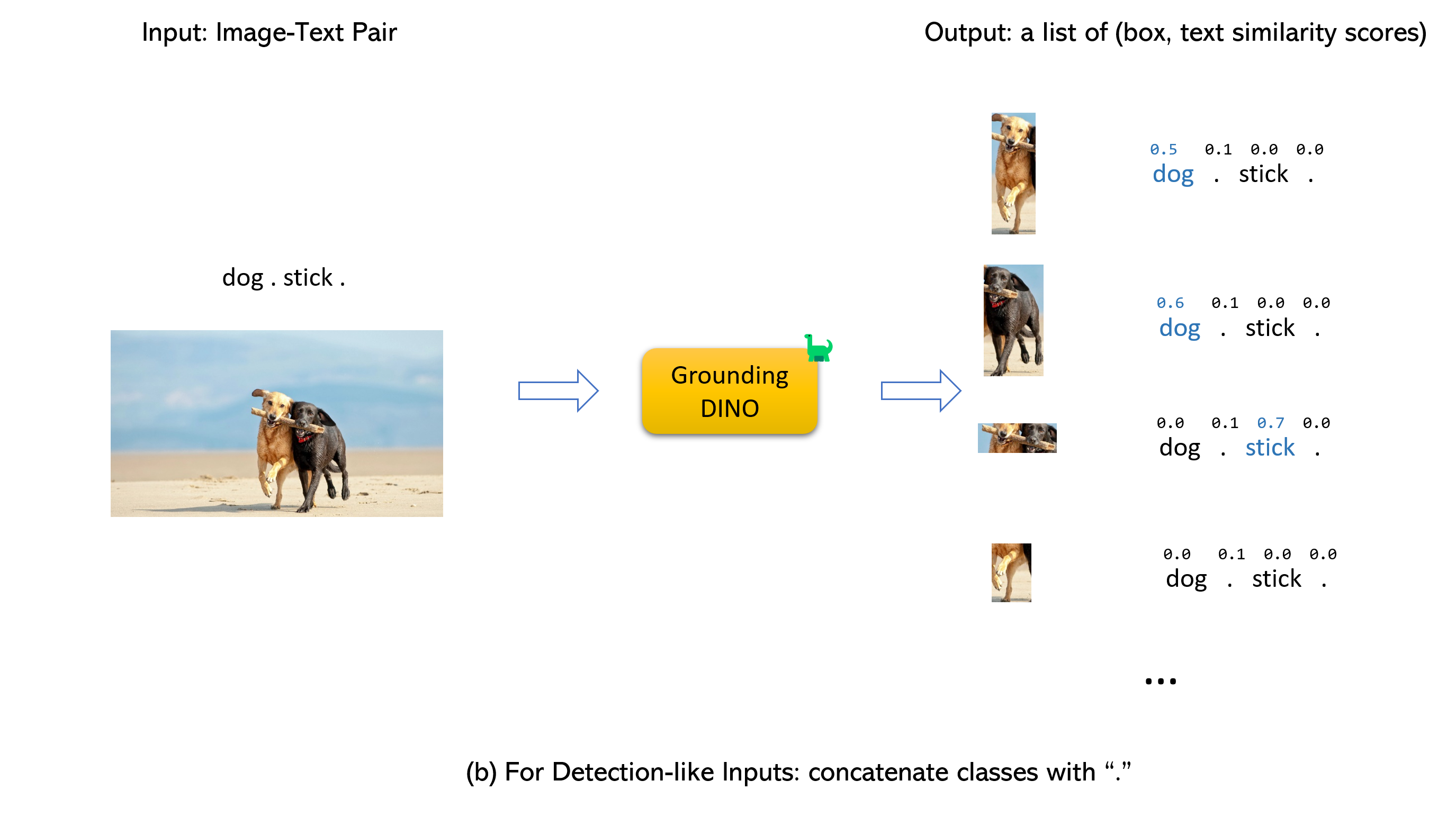
- 一个广泛应用标注框架,原理是把图片做切分,然后和 text 做相似度匹配,
Grounding DINO accepts an (image, text) pair as inputs.
It outputs 900 (by default) object boxes. Each box has similarity scores across all input words. (as shown in Figures below.)
We defaultly choose the boxes whose highest similarities are higher than a box_threshold.
We extract the words whose similarities are higher than the text_threshold as predicted labels.
If you want to obtain objects of specific phrases, like the dogs in the sentence two dogs with a stick., you can select the boxes with highest text similarities with dogs as final outputs.
Note that each word can be split to more than one tokens with different tokenlizers. The number of words in a sentence may not equal to the number of text tokens.
We suggest separating different category names with . for Grounding DINO.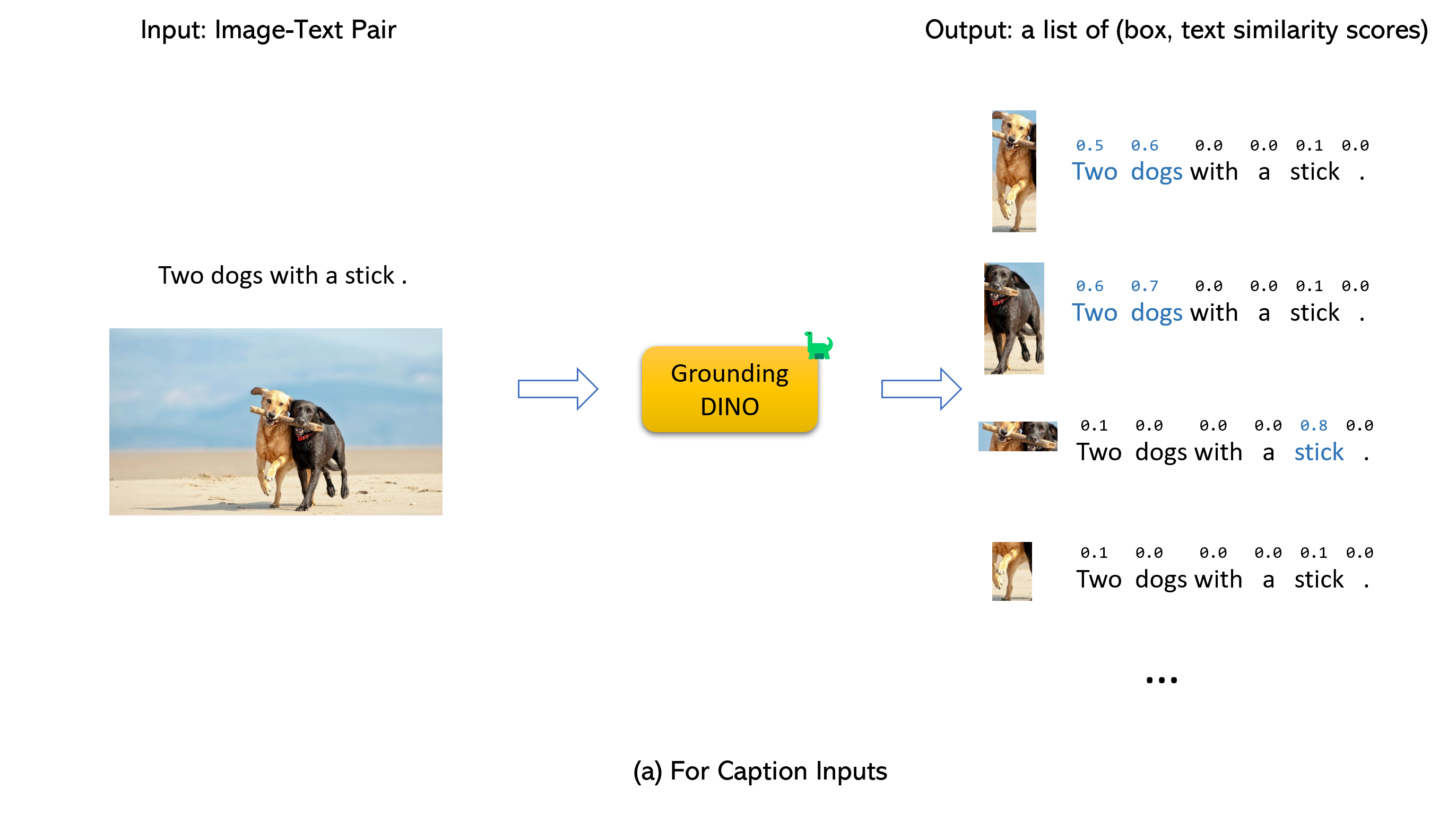
Infra
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
- 26.1.12 by deepseek
- 提出一个有意思的观点,
Since standard Transformers (Vaswani et al., 2017) lack a native knowledge lookup primitive, current LLMs are forced to simulate retrieval through computation,是说对于一些知识类问题, transformer 是通过计算来得到结果,但实际上并不需要计算,只需要一个巨大的 lookup table 就可以了。 - n-gram demo: https://github.com/deepseek-ai/Engram/blob/main/engram_demo_v1.py
- 在 transformer 中插入一个 Engram,然后:
- tokenizer 后的 inputs 做了 projection layer 映射到一个更小的词表
- hash 映射:multi-head hasing 避免 hash 冲突,用 n-gram 查 hash 表
- 为了让 lookup 出来的 embedding 更有上下文信息,采用 attention 的做法,把 inputs 作为 query 去点查 embedding 的 k 和 v,拿到输出结果
- training 的时候 n-gram 通过 gpu all-to-all 传播(应该也是多级缓存),serving 的时候用外存(多级),如果 n 不是太大的话,好像对于内存来说还好(具体数值要算一下)

Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings
-
25 年 4 月份发的,主要是 LanceDB 公司,lance format 是开源项目,lancedb 是商业化产品
-
主要是解决 parquet 里对于大 value 不友好的问题 1) meta 和 data 分开存,多次 IO,2) page 的结构在大 value 下引入大量 meta 导致 oom
-
用了一个 HF 的图片 dataset 实测下来体感一般,压缩效率没有 parquet 好(和论文有出入,但是和其他实际使用者聊下来体感类似),但确实提供了一些 emb search 的能力,关键点是不确定是否能够 scale
-
不是一个 evaluation 框架,提供了一个 evalution 环境,解决真实场景里 evalution 成本高的问题